
Prawdopodobieństwo warunkowe i algorytm, który zadziwi Twoją panią od polskiego
15.06.2010 - Krzysztof Dryś
 Pytanie o sensPo co nam to wszystko? Oczywiście - pokazaliśmy szybki algorytm, który rozwiązuje ciekawy problem. Ale czy to koniec? Nie! Przecież, zgodnie z obietnicą, mamy zobaczyć jakieś ciekawego jego zastosowanie!
Przede wszystkim: czy korzystaliśmy w tym algorytmie z tego, że w wyniku rzutu monetą
możne wypaść tylko orzeł albo reszka? Otóż nie! Możemy nasze monety zastąpić
kostkami, z których każda ma wiele ścianek. A więc rzut nią może dać wiele wyników.
Wystarczy, że zamiast tablicy w[orzeł, reszka][1...n] wejściem naszego algorytmu będzie tablica
w[1...L][1...n], gdzie Teraz zobaczymy, jak wykorzystać wszystkie rozważania, do zbudowania naszego algorytmu. Będziemy musieli wykorzystać naszą metaforę z kostkami do granic możliwości. Teraz bowiem kostkami (albo monetami) będą części mowy. Na przykład: rzeczownik, r. męski, l .mnoga będzie jedną kostką, a czasownik, rodzaj męski, czas przeszły inną.
Skoro kostki są takie dziwne, to jak się nimi rzuca? Załóżmy, że mamy bardzo długi tekst w języku polskim. Może się on na przykład składać ze wszystkich książek wydanych po 1945 roku. Rzut kostką
Tablica Poza tym, że nasze monety stały się trochę bardziej skomplikowane (i jest ich bardzo dużo), nic się nie zmieniło. Nasz poprzedni algorytm powinien zadziałać i tym razem. Wyznaczy on ciąg części mowy, które najlepiej tłumaczą słowa w zdaniu. Oczywiście nie mamy pewności, że to będzie właśnie poprawny ciąg części mowy słów w zdaniu. Ale możemy powiedzieć, że wedle naszej wiedzy jest najbardziej prawdopodobny ze wszystkich ciągów. Zastanówmy się, jeszcze czy ten algorytm ma sens. Jeżeli wpiszemy mu zapytanie: biegli wydali wyrok, program odpowie, że biegli to przymiotnik, wydali to czasownik, a wyrok to rzeczownik. A co nasz program odpowie na zapytanie: chłopcy biegli do domu? Ponownie stwierdzi, że słowo biegli to przymiotnik. Skąd ona wynika? Otóż pary rzeczownik przymiotnik i przymiotnik czasownik są częste (np. sok pomarańczowy i właśnie biegli wydali (wyrok) ). A nasz algorytm uwzględnia tylko jednowyrazowy kontekst każdego słowa. I to już wszystko. Znaleźliśmy zastosowanie dla naszego algorytmu: nazywanie części mowy w zdaniu. Oczywiście nie jest to jedyne zastosowanie, ale chyba jedno z najbardziej widowiskowych. Ten algorytm naprawdę jest tak wykorzystywany!
(1 ocena) |
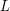 to liczba możliwych rzutów kostką.
to liczba możliwych rzutów kostką.
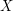 (gdzie
(gdzie ![$ p[X][Y] $](/files/tex/37caa8fc4d352956b46aed5cf5b20acb288297cb.png) ma równie łatwą interpretację. Mówi ona, jakie jest prawdopodobieństwo, że wybrane losowo z naszego długiego tekstu słowo jest częścią mowy
ma równie łatwą interpretację. Mówi ona, jakie jest prawdopodobieństwo, że wybrane losowo z naszego długiego tekstu słowo jest częścią mowy 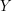 , pod warunkiem, że poprzednie słowo jest częścią mowy
, pod warunkiem, że poprzednie słowo jest częścią mowy Pod patronatem:



Informacje
- O portalu
- Autorzy
- Mapa portalu
- Zgłoś błąd
Copyright © 2008-2010 Wrocławski Portal Informatyczny
design: rafalpolito.com