
Bezbolesne wprowadzenie do MapReduce
16.12.2009 - Paweł Ledwoń
  W chwili pisania tego artykułu w Internecie znajdowało się grubo ponad bilion (tak, 1012) dostępnych dla wyszukiwarek stron WWW. Uporządkowanie tak dużej kolekcji dokumentów jest nietrywialnym zadaniem, które wymaga znacznego nakładu pracy. Oczywiście żaden komputer nie poradzi sobie z tym problemem w pojedynkę. Nie poradzi sobie z nim też 5 czy 10 komputerów. Trzeba do tego celu wykorzystać znacznie większą ilość maszyn. MapReduce jest systemem przeznaczonym do tworzenia aplikacji działających jednoczenie na tysiącach przeciętnej jakości komputerów. Liczby mówią same za siebie – w 2008 roku Google było w stanie posortować 1 petabajt danych w 6 godzin i 2 minuty. Użyto do tego celu 4000 serwerów, a dane były zapisane na 48,000 dysków twardych. Dziennie Google przetwarza za pomocą MapReduce dziesiątki petabajtów danych. Problem zarządzania nieprzeciętnie dużą ilością danych dotyczy szczególnie wyszukiwarek internetowych. Gwałtowny rozrost Internetu spowodował, że muszą one przechowywać niewyobrażalne ilości danych, aby udzielić trafnej odpowiedzi na zadawane im zapytania. Zanim jednak możliwe będzie przetwarzanie zapytań, na podstawie pobranych danych musi zostać utworzony indeks, który umożliwi szybkie przeszukiwanie zgromadzonych dokumentów. Mimo prostoty niektórych rozwiązań tego problemu, wymagana jest znaczna ilość zasobów, żeby móc wprowadzić je w życie. Jednymi z programistów, którzy musieli stawić czoło temu problemowi, byli pracownicy Google. Potrzebowali stworzyć system, który zapewni dalsze funkcjonowanie usług, mimo rosnącej ilości składowanych informacji. Google posiadało liczną armię serwerów, jednak były to tanie, niewiele różniące się od domowych komputerów. Wykorzystanie liczebności było jedyną szansą na sukces. Nie wystarczy pójść do sklepu, kupić tysiąc
komputerów i liczyć na to, że wszystko będzie działać. Zakładając, że każdy z
serwerów ma przed sobą średnio trzy lata pracy pod wysokim obciążeniem, musimy
liczyć się z tym, że prędzej czy później pojawią się problemy. Uśredniając,
codziennie powinniśmy spodziewać się jednej awarii. Nie można przejść obojętnie
obok tych liczb, musimy uwzgędnić w projekcie oprogramowania przyszłe awarie
systemu.
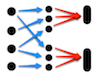
W roku 2004 pracownicy Google Jeffrey Dean i Sanjay Ghemawat zaprezentowali pracę „MapReduce: Simplified Data Processing on Large Clusters”. W dalszej części artykułu omówimy przedstawiony w niej system i zademonstrujemy jego działanie na kilku ciekawych przykładach. MapReduce = map + reduceJak wskazuje tytuł rozdziału, w MapReduce mamy do czynienia z dwiema fazami obliczeń, które możemy po polsku nazwać mapowaniem i redukcją. Jednak wcześniej musimy przygotować dane, które będą przedmiotem obliczeń. Dane wejściowePierwszym krokiem jest określenie danych wejściowych. MapReduce wymaga, aby była nimi lista par kluczy i przypisanych im wartości. Źródło danych może być dowolne – czytanie z pliku czy bazy danych są najpopularniejszymi metodami dostarczania danych. Odpowiedzialność za pobranie danych leży więc po stronie programisty. MapPierwszą fazą obliczeń jest mapowanie – operacja znana z funkcyjnych języków programowania. Programista dostarcza funkcję map, przyjmującą jako argument parę składającą się z klucza k i wartości v (typów odpowiednio K i V), która pochodzi z danych wejściowych. Na ich podstawie wyliczana jest lista pośrednich par kluczy i wartości, mających być może nowe typy K' i V'. Typ funkcji map przedstawia się zatem następująco:
ReducePo zakończeniu mapowania dane są sortowane, grupowane względem kluczy pośrednich i przekazywane do funkcji reduce. Można więc wywnioskować, że funkcja reduce przyjmuje jako argumenty klucz k' typu K' i listę wartości (v'1, v'2, …, v'n) typu V' wygenerowanych przez funkcję map. Zadaniem funkcji reduce jest łączenie danych i przygotowanie ostatecznej listy wartości, również typu V'. W typowych scenariuszach listy zwracane przez reduce mają jednak tylko jeden element. Wynik redukcji jest zapisywany jako końcowy efekt obliczeń.
Schemat działania systemuPrzed rozpoczęciem obliczeń musimy określić liczby M i R oznaczające odpowiednio ilość zadań map i reduce. Dane wejściowe dzielone są na M części, każda z osobna przetwarzana jest w całości na jednym z serwerów. Wartość M może być większa niż liczba posiadanych maszyn – wtedy niektóre z nich będą zmuszone do wykonania kilku zadań. Analogicznie postępujemy przy zadaniach reduce – dzielimy dane pośrednie na R fragmentów i rozpraszamy obliczenia między serwery. Przed wywołaniami reduce dochodzi jeszcze wstępne sortowanie i grupowanie, również wykonywane już lokalnie. Wyniki z funkcji reduce zapisywane są do plików – każdy fragment danych pośrednich generuje jeden plik wyjściowy. Nad przydziałem zadań czuwa specjalnie wybrany do tego serwer główny. Pozostałe serwery wykonują przekazane im polecenia. Cały przebieg obliczeń można przedstawić następująco:
Naprawdę to wszystko?Jak widać, MapReduce jest bardzo uproszczonym modelem, jednak zaskakująco duża liczba często spotykanych problemów daje się w nim wyrazić w przejrzysty sposób. Dzięki wprowadzonym ograniczeniom podział obliczeń między serwery staje się dużo łatwiejszy. Wywołania funkcji map i reduce dla różnych kluczy mogą być wykonywane na różnych komputerach z racji niezależności przetwarzanych danych. Sam MapReduce nie jest wystarczającym rozwiązaniem w większości sytuacji. Niezbędnym składnikiem całego systemu jest system plików, na którym będą przechowywane wszystkie dane wczytywane i generowane przez zadania MapReduce. System ten musi również działać na wielu komputerach, najlepiej równolege z MapReduce. Dodatkowo, wygodnie używać baz danych, które działają lepiej dla ustrukturyzowanych danych. Google zadbało o implementację tych komponentów, które nazwało odpowiednio GFS (Google File System) i BigTable. Prace związane z nimi możemy znaleźć w Internecie na stronach Google Research. Nie dajmy się jednak oszukać prostym interfejsem – implementacja całego systemu MapReduce jest zadaniem nieporównywalnie trudniejszym niż jego wykorzystanie i zasługuje na osobny artykuł. (3 ocen) |
Pod patronatem:



Informacje
- O portalu
- Autorzy
- Mapa portalu
- Zgłoś błąd
Copyright © 2008-2010 Wrocławski Portal Informatyczny
design: rafalpolito.com