
Znajdowanie otoczki wypukłej jest jednym z podstawowych problemów w geometrii obliczeniowej. Fakt, że w ciągu ostatnich 50 lat powstało bardzo wiele publikacji na temat tego zagadnienia świadczy o jego znaczeniu w dziedzinie algorytmiki. W niniejszym artykule zajmiemy się znajdowaniem otoczki wypukłej na płaszczyźnie.
Można oczywiście rozważać przestrzeń trójwymiarową (lub jeszcze większą), lecz sformułowany w takich przestrzeniach problem i jego rozwiązanie zazwyczaj ciężko jest zobrazować. Mimo to wspomnimy o kilku algorytmach działających w trzech wymiarach, lecz nie będziemy się zbytnio w nie zagłębiać.Od razu zaczniemy od definicji, gdyż jest na tyle prosta i intuicyjna, że każdy powinien ją bez trudu zrozumieć:
Otoczka wypukła (convex hull) zbioru punktów 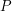 to najmniejszy wielokąt wypukły taki, że każdy punkt ze zbioru leży albo na brzegu wielokąta albo w jego wnętrzu. W skrócie będziemy zapisywali:
to najmniejszy wielokąt wypukły taki, że każdy punkt ze zbioru leży albo na brzegu wielokąta albo w jego wnętrzu. W skrócie będziemy zapisywali: 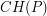 .
.
Otoczkę wypukłą w łatwy sposób można sobie wyobrazić. Załóżmy, że zamiast zbioru punktów mamy gwoździe, które są przybite w kilkunastu miejscach na jakiejś płaskiej powierzchni:

Weźmy teraz gumkę recepturkę, rozciągnijmy ją i nałóżmy na wszystkie wystające gwoździe:
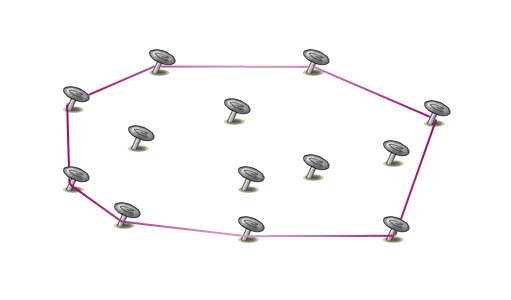
Gumka przyjęła kształt wielokąta wypukłego, a wszystkie gwoździe albo stykają się z gumką od wewnętrznej strony, albo znajdują się wewnątrz gumki. Tak ustawiona gumka jest otoczką wypukłą dla danego zbioru gwoździ.
W kolejnej części artykułu zajmiemy się kilkoma popularnymi metodami znajdowania otoczki wypukłej na płaszczyźnie. Zapiszemy każdy z algorytmów w postaci pseudokodu oraz przeanalizujemy pod kątem złożoności czasowej. Zapraszam wszystkich zainteresowanych do lektury.
Pakowanie prezentu jest jedną z najprostszych metod znajdowania otoczki wypukłej (alternatywnie można też na nią mówić algorytm Jarvisa, od nazwiska matematyka, który ją wymyślił). Niejednego pewnie zastanawia skąd wziął się taki dziwny pomysł na nazwanie algorytmu? Wszystkie wątpliwości powinna wyjaśnić poniższa animacja:

Algorytm Jarvisa można intuicyjnie opisać w następujący sposób: jeśli popatrzymy na czerwoną półprostą jako na kawałek papieru, to algorytm opakowuje ciasno cały zbiór punktów. Zaczynamy od zamocowania jednego końca taśmy papierowej do najbardziej wysuniętego na prawo punktu. Następnie owijamy wszystkie punkty dookoła. Kończymy owijanie, gdy wrócimy do miejsca, z którego zaczynaliśmy.
Widzimy „na oko”, że to działa. Wielokąt wypukły, który powstanie po opakowaniu wszystkich punktów faktycznie jest ich otoczką wypukłą. Dowody „na wiarę” nie są jednak zbyt fascynujące, dlatego powinniśmy przedstawić jakiś konkretny argument przemawiający za poprawnością nowo poznanej metody.
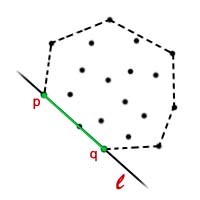
Mamy dany zbiór punktów . Zamiast patrzeć na całą otoczkę spójrzmy jedynie na którąkolwiek z krawędzi, która do niej należy. Taka krawędź łączy dwa punkty, które nazwiemy  i
i  . Łatwo jest dostrzec, że wszystkie inne punkty ze zbioru muszą: albo leżeć na krawędzi
. Łatwo jest dostrzec, że wszystkie inne punkty ze zbioru muszą: albo leżeć na krawędzi  , albo znajdować się po jednej stronie prostej
, albo znajdować się po jednej stronie prostej  , którą wyznaczają punkty i . Twierdzenie odwrotne również zachodzi. Podsumowując:
, którą wyznaczają punkty i . Twierdzenie odwrotne również zachodzi. Podsumowując:
należy do otoczki wypukłej wtedy i tylko wtedy, gdy wszystkie inne punkty leżą na lub po jednej ze stron tej krawędzi.Teraz widać, że pakowanie prezentu rzeczywiście wyznacza otoczkę wypukłą, gdyż kolejne krawędzie dołączane do otoczki spełniają powyższy warunek.
Pora przedstawić procedurę, która odwzorowuję naszą intuicję o pakowaniu prezentu. Nie będziemy jednak fizycznie tworzyli półprostej obracającej się wokół własnej osi. Takie podejście jest nieefektywne i niepoprawne. „Pakowanie” to tylko sposób myślenia o rozwiązaniu naszego problemu. W rzeczywistości do odkrywania kolejnych punktów otoczki posłużymy się twierdzeniem z poprzedniego akapitu. Przeanalizujmy poniższy algorytm:

Oto znaczenie zmiennych i struktur użytych w procedurze  :
:
![$ P[1..n] $](/files/tex/c5086e0dcd31c9348ba95f854c1e228de6a375ef.png) – tablica punktów płaszczyzny podanych na wejściu
– tablica punktów płaszczyzny podanych na wejściu![$ CH[1..n] $](/files/tex/b8f88e62d6d37a1e98f98fdf9e75be391f9abce6.png) – tablica, w której przechowywane są kolejne punkty należące do otoczki wypukłej. Wielkość tej tablicy to
– tablica, w której przechowywane są kolejne punkty należące do otoczki wypukłej. Wielkość tej tablicy to  , ponieważ może się zdarzyć, że każdy punkt z należy do otoczki (w większości przypadków będzie ich znacznie mniej).
, ponieważ może się zdarzyć, że każdy punkt z należy do otoczki (w większości przypadków będzie ich znacznie mniej). – jest to zmienna przechowująca punkt, który na pewno znajdzie się w otoczce.
– jest to zmienna przechowująca punkt, który na pewno znajdzie się w otoczce.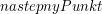 – zmienna pomocnicza, która przechowuje kandydatów na kolejny punkt otoczki
– zmienna pomocnicza, która przechowuje kandydatów na kolejny punkt otoczkiAlgorytm działa następująco:
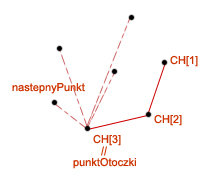
1. Wyznaczamy punkt startowy. Jest to taki punkt ze zbioru , który na pewno znajdzie się w rozwiązaniu. Nie ma chyba żadnych wątpliwości, że punkt, który znajduje się najbardziej na prawo spełnia nasze założenia. Przypisujemy ten punkt do zmiennej . Kolejnych punktów otoczki będziemy szukali zgodnie z ruchem wskazówek zegara.
2. Wchodzimy w pętle zewnętrzną. Dodajemy znaleziony punkt otoczki do rozwiązania.
3. Szukamy następnego punktu otoczki, który będziemy przechowywać w zmiennej . Teraz najważniejsze: chcemy, aby kolejny punkt wraz z ostatnio znalezionym punktem otoczki utworzyli krawędź skierowaną ![$ \{ CH[i], nastepnyPunkt \} $](/files/tex/044dbb6f8f34690be7eab2d545b599cae70a8b7a.png) taką, że wszystkie inne punkty ze zbioru leżą na prawo od niej.
Taki punkt można wyznaczyć w bardzo prosty sposób. Najpierw do zmiennej przypisujemy pierwszy element zbioru . W pętli wewnętrznej sprawdzamy kolejne elementy zbioru . Jeśli zdarzy się, że w
taką, że wszystkie inne punkty ze zbioru leżą na prawo od niej.
Taki punkt można wyznaczyć w bardzo prosty sposób. Najpierw do zmiennej przypisujemy pierwszy element zbioru . W pętli wewnętrznej sprawdzamy kolejne elementy zbioru . Jeśli zdarzy się, że w 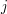 -tej iteracji punkt
-tej iteracji punkt ![$ P[j] $](/files/tex/3f323be402bcb2bf644443d98bbc24ad25a40c28.png) znajduje się na lewo od krawędzi , to aktualizujemy zmienną przypisując jej nową wartość: . Aby wykonać tego sprawdzenia posłużymy się pomocniczą procedurą
znajduje się na lewo od krawędzi , to aktualizujemy zmienną przypisując jej nową wartość: . Aby wykonać tego sprawdzenia posłużymy się pomocniczą procedurą 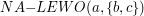 , która wyznacza, po której stronie krawędzi
, która wyznacza, po której stronie krawędzi 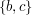 znajduje się punkt
znajduje się punkt  . Po opuszczeniu pętli w zmiennej znajdować się będzie kolejny punkt należący do otoczki wypukłej. Wartość tą przypisujemy zmiennej .
. Po opuszczeniu pętli w zmiennej znajdować się będzie kolejny punkt należący do otoczki wypukłej. Wartość tą przypisujemy zmiennej .
Mała dygresja: warto zauważyć, że wyznaczenie kolejnego punktu otoczki jest bardzo podobne do szukania największego elementu ze zbioru liczb. Najpierw przyjmujemy, że największym element jest pierwszy ze zbioru. Następnie przechodzimy od lewej do prawej cały zbiór i aktualizujemy naszego "maxa", jeśli któryś z elementów jest od niego większy. W algorytmie Jarvisa zbiór liczb zamieniamy na zbiór punktów, a relację "mniejszy-równy" na relację "na-lewo-od".
4. Jeśli następny punkt otoczki jest za razem pierwszym, to algorytm się kończy. W przeciwnym razie wracamy do kroku 2.
Poprawność algorytmu wynika wprost z udowodnionego wcześniej twierdzenia.
W naszym algorytmie wykorzystaliśmy pomocniczą funkcję 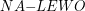 , która dla danego punktu i skierowanego odcinka sprawdzała, po której stronie odcinka leży ten punkt. Oto definicja tej funkcji:
, która dla danego punktu i skierowanego odcinka sprawdzała, po której stronie odcinka leży ten punkt. Oto definicja tej funkcji:
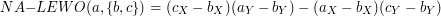
Jeśli zwrócona wartość jest:
leży na lewo od odcinka leży na prawo od odcinka ,  oraz
oraz  są współliniowe (czyli leżą na jednej prostej). Ten przypadek omówimy osobno na następnej stronie.
są współliniowe (czyli leżą na jednej prostej). Ten przypadek omówimy osobno na następnej stronie.
Mała uwaga: jeśli nie jesteś do końca przekonany, że powyższy wzór jest poprawny, to polecam przeczytanie artykułu pt. "Krótki wstęp do algorytmów geometrycznych" [1].
Algorytm Jarvisa jest na tyle prosty, że nie będziemy mieli problemów z analizą jego złożoności. Zauważmy, że wewnętrzna pętla przebiega po wszystkich punktach, a zewnętrzna pętla wykona się dokładnie tyle razy, ile punktów leży na otoczce wypukłej. Podsumowując, jeśli oznaczymy liczbę punktów otoczki jako  , to dokładnie razy będziemy musieli przejrzeć tablicę rozmiaru . Z tego wniosek, że złożoność czasowa algorytmu pakowania prezentu to
, to dokładnie razy będziemy musieli przejrzeć tablicę rozmiaru . Z tego wniosek, że złożoność czasowa algorytmu pakowania prezentu to 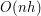 .
.
Zwróćmy uwagę na to, że czas jest zależny od wyniku. Nie jesteśmy w stanie przewidzieć wartości przed uruchomieniem procedury , chociaż w niektórych przypadkach można dokonać pewnych oszacowań, ale to już zależy od rozwiązywanego problemu. Czy warto więc stosować algorytm Jarvisa? Na pewno wielką zaletą jest jego prosta idea i łatwość implementacji. Należy jednak pamiętać, że dla pewnych złośliwych danych (np. gdy wszystkie punkty leżą na obwodzie koła) czas działania może wynieść nawet 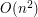 .
.
Zanim poznamy następną metodę wyznaczającą otoczkę wypukłą chciałbym przekazać wszystkim bardzo smutną nowinę. Otóż okazuje się, że jeśli zapisalibyśmy procedurę z poprzedniej strony w jakimkolwiek języku programowania, to nie będzie ona działać poprawnie (przynajmniej nie dla wszystkich zestawów danych).
Dzieje się tak dlatego, że podczas zapisywania procedury w pseudokodzie pominęliśmy tzw. przypadki zdegenerowane. Trudno jest precyzyjnie zdefiniować czym tak właściwie są przypadki zdegenerowane. W algorytmach rozwiązujących problemy geometryczne są to pewne specyficzne ustawienia punktów, odcinków, prostych, figur itp. Takie ustawienia sprawiają, że struktury danych lub techniki użyte w algorytmach geometrycznych źle interpretują część danych wejściowych co prowadzi do katastrofy.
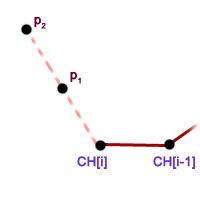
Gdzie w algorytmie Jarvisa możemy wpaść w pułapkę? Zastanówmy się, jak działałby nasz algorytm, w sytuacji gdy trzy kolejne punkty otoczki leżałyby na jednej prostej. Załóżmy, że jesteśmy w jakimś momencie wykonywania obliczeń, znaleźliśmy następny punkt otoczki, wracamy do początku pętli zewnętrznej i napotykamy na sytuację z rysunku obok.Wchodzimy do pętli wewnętrznej. Jeśli jako pierwszy na kandydata zostanie wybrany punkt 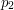 , to krok zostanie wykonany poprawnie, bo porównanie punktów
, to krok zostanie wykonany poprawnie, bo porównanie punktów 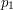 i nie zmieni stanu zmiennej . Jednak jeśli pierwszym kandydatem będzie , to ostateczne rozwiązanie będzie niepoprawne. Zauważmy, że w następnym kroku wzięlibyśmy do otoczki i oba te punkty należałyby do wyniku. Kłóci się to z definicją otoczki wypukłej. Chcemy aby wielokąt zawierający wszystkie punkty był najmniejszy nie tylko w sensie pola powierzchni, ale także ilości boków.
i nie zmieni stanu zmiennej . Jednak jeśli pierwszym kandydatem będzie , to ostateczne rozwiązanie będzie niepoprawne. Zauważmy, że w następnym kroku wzięlibyśmy do otoczki i oba te punkty należałyby do wyniku. Kłóci się to z definicją otoczki wypukłej. Chcemy aby wielokąt zawierający wszystkie punkty był najmniejszy nie tylko w sensie pola powierzchni, ale także ilości boków.
Punkt powinien zostać pominięty w rozwiązaniu. Jak sobie z tym poradzić? Każdy pewnie zna wzór na odległość dwóch punktów na płaszczyźnie. Wystarczy użyć tego wzoru gdy napotkamy na sytuację, gdy dwa kolejne punkty wraz z ostatnio znalezionym punktem otoczki leżą na jednej prostej. Sprawdzamy odległość dwóch następnych kandydatów od ostatnio dodanego punktu otoczki, czyli porównujemy ze sobą długość dwóch odcinków: ![$ \{CH[i],p_1\} $](/files/tex/d2d929f4e04b5953483587dc52f19126eed88897.png) i
i ![$ \{CH[i],p_2\} $](/files/tex/b5df524bd922ad4053df16b3f32c26a9beaba2e6.png) . Dłuższy odcinek wygrywa, a jego koniec zostaje nowym kandydatem na następny punkt otoczki.
. Dłuższy odcinek wygrywa, a jego koniec zostaje nowym kandydatem na następny punkt otoczki.
Podsumowując: jedyne co trzeba zrobić, to dodać jeszcze jeden warunek do pętli wewnętrznej sprawdzający czy funkcja zwróciła warość zero. Myślę, że każdy z łatwością poradzi sobie z wprowadzeniem odpowiednich modyfikacji.
Pozostaje jeszcze jedna kwestia: dlaczego od razu nie zapisaliśmy tego warunku w pseudokodzie? Odpowiedź: ponieważ łatwiej jest nam myśleć o idei algorytmu używając ougólnionych danych. Gdybyśmy od razu zaczęli wymyślać jakieś złośliwe dane i na bierząco starać się z nimi walczyć, to w końcu byśmy się w tym wszystkim pogubili i zrobiłoby się nam smutno. Co prawda w algorytmie Jarvisa nie ma trudności z przypadkami zdegenerowanymi, ale im bardziej wgłębiamy się w świat geometrii obliczeniowej, tym więcej napotykamy algorytmów, gdzie przypadki brzegowe i zdegenerowane występują w takiej ilości, że zaczyna boleć głowa.
Na zakończenie tego działu, dobra rada: myślmy ogólnie, myślmy prościej :)
W tym rozdziale omówimy bardziej efektywny algorytm znajdowania otoczki wypukłej. Jest on w większości przypadków znacznie szybszy od metody pakowania prezentu i czas jego działania nie zależy od rozmiaru wyniku. Jedyne co wzrośnie, to poziom skomplikowania, ale tylko nieznacznie. Tak jak pakowanie prezentu, algorytm Grahama jest również jednym z popularniejszych rozwiązań problemu otoczki wypukłej.
W algorytmie Grahama - zanim przystąpimy do właściwego wyznaczania rozwiązania – dane muszą być wcześniej odpowiednio przygotowane. Mianowicie, wszystkie punkty ze zbioru muszą zostać posortowane i to nie w byle jaki sposób. Otóż punkty sortować będziemy kątowo względem punktu startowego.
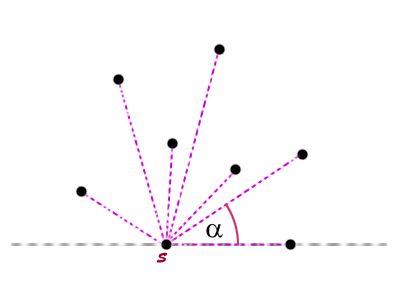
Punkt startowy (oznaczony literą  ) wyznaczamy w prosty sposób: bierzemy punkt, który znajduje się najbardziej na dole (czyli taki, który ma najmniejszą współrzędną
) wyznaczamy w prosty sposób: bierzemy punkt, który znajduje się najbardziej na dole (czyli taki, który ma najmniejszą współrzędną  ), a jeśli takich punktów jest kilka, to wybieramy ten najbardziej na lewo (czyli taki, który ma najmniejszą współrzędną
), a jeśli takich punktów jest kilka, to wybieramy ten najbardziej na lewo (czyli taki, który ma najmniejszą współrzędną  ). Nie trudno zauważyć, że punkt startowy będzie częścią otoczki.
). Nie trudno zauważyć, że punkt startowy będzie częścią otoczki.
Punkt startowy ustawiamy na początku zbioru (![$ P[1] = S $](/files/tex/c4bdc70cb7149aaea072e761b84063394725509b.png) ). Sortujemy tablicę
). Sortujemy tablicę ![$ P[2..n] $](/files/tex/6c45923d85b4954fe4d0a78f516acd9061711386.png) kątowo względem
kątowo względem ![$ P[1] $](/files/tex/d9fd1aa6642943d9de4d3a462e49bc6c5c5ca796.png) . Oznacza to, że pierwszym elementem zbioru ma być punkt, który tworzy najmniejszy kąt z punktem i prostą równoległą do osi
. Oznacza to, że pierwszym elementem zbioru ma być punkt, który tworzy najmniejszy kąt z punktem i prostą równoległą do osi 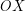 przechodzącą przez (patrz rysunek powyżej).
przechodzącą przez (patrz rysunek powyżej).
Do sortowania można wykorzystać jakąkolwiek znaną metodę np. quicksort, heapsort lub margesort. Ważne, aby sortownie przebiegało jak najszybciej (najlepiej w 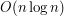 ), bo jak się później okażę, w algorytmie Grahama sortowanie zabiera najwięcej czasu i dominuje czas właściwego wyznaczania otoczki.
), bo jak się później okażę, w algorytmie Grahama sortowanie zabiera najwięcej czasu i dominuje czas właściwego wyznaczania otoczki.
Zachodzi pytanie: jak wyznaczyć te wszystkie kąty? Ja proponuję zadać inne pytanie: czy w ogóle trzeba je wyznaczyć? Okazuje się, że nie. Zauważmy, że wartość każdego z kątów należy do przedziału 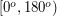 . Wynika to z wyboru punktu startowego. Teraz wystarczy przypomnieć sobie z lekcji matematyki, że funkcja cosinus jest monotoniczna właśnie w tym przedziale, a wyznaczenie cosinusa z szukanego kąta jest o wiele prostsze, bo wymaga tylko kilku operacji arytmetycznych. Wyszperanie odpowiednich wzorów z licealnych (a nawet gimnazjalnych) książek pozostawiam czytelnikowi.
. Wynika to z wyboru punktu startowego. Teraz wystarczy przypomnieć sobie z lekcji matematyki, że funkcja cosinus jest monotoniczna właśnie w tym przedziale, a wyznaczenie cosinusa z szukanego kąta jest o wiele prostsze, bo wymaga tylko kilku operacji arytmetycznych. Wyszperanie odpowiednich wzorów z licealnych (a nawet gimnazjalnych) książek pozostawiam czytelnikowi.
Mając posortowane punkty można wreszcie przejść do sedna naszego algorytmu.
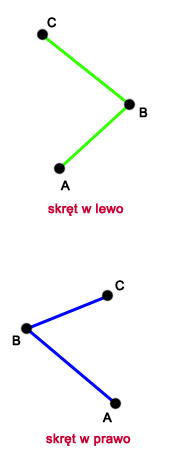
Otoczkę wypukłą będziemy budowali w kierunku odwrotnym do ruchu wskazówek zegara. Zauważmy, że jeśli weźmiemy gotową otoczkę wypukłą, wyszczególnimy jakikolwiek jej punkt i przejdziemy po całej otoczce w kierunku odwrotnym do ruchu wskazówek zegara, to każde trzy kolejne punkty będą tworzyły tzw. skręt w lewo (patrz rysunek obok). W algorytmie Grahama korzystamy właśnie z tego faktu. Zauważmy też, że skręt w lewo (lub prawo) można łatwo wykryć w czasie stałym korzystając ze znanej już procedury .
Kolejnych kandydatów na otoczkę wypukłą będziemy umieszczali na pomocniczym stosie 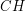 . Po zakończeniu działania algorytmu w będą się znajdowały kolejne punkty otoczki. Ogólną ideę działania algorytmu można opisać w następujący sposób:
. Po zakończeniu działania algorytmu w będą się znajdowały kolejne punkty otoczki. Ogólną ideę działania algorytmu można opisać w następujący sposób:
1. Pierwsze dwa punkty ze zbioru umieszczamy na stosie (pamiętamy, że tablica jest już posortowana )
2. Układamy kolejne punkty ze zbioru na stosie dopóki tworzą - wraz z dwoma elementami na szczycie stosu - skręt w lewo.
3. Jeśli doszliśmy do punktu startowego, algorytm się kończy. W przeciwnym razie napotkaliśmy miejsce, gdzie kolejny punkt z wraz z dwoma elementami na szczycie stosu tworzą skręt w prawo. Nazwijmy te punkty kolejno 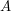 ,
, 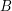 , i
, i 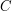 (patrz rysunek obok; niebieskie krawędzie). i leżą na stosie, a jest kolejnym punktem z . Widać, że w takim wypadku punkt na pewno nie będzie należał do otoczki. Może być kuszące, aby połączyć po prostu punkt z , ale niestety nie jest to poprawne podejście. Mianowicie, może się okazać, że następny element ze stosu (znajdujący się poniżej ) po połączeniu z wykluczy z bycia częścią otoczki. Może to też być jakiś inny element ze stosu. Co należy zrobić, to usuwać ze stosu kolejne elementy dopóki nie będzie spełniony warunek skrętu w lewo. Przykład "naprawienia własności skrętu w lewo" demonstruje poniższa animacja:
(patrz rysunek obok; niebieskie krawędzie). i leżą na stosie, a jest kolejnym punktem z . Widać, że w takim wypadku punkt na pewno nie będzie należał do otoczki. Może być kuszące, aby połączyć po prostu punkt z , ale niestety nie jest to poprawne podejście. Mianowicie, może się okazać, że następny element ze stosu (znajdujący się poniżej ) po połączeniu z wykluczy z bycia częścią otoczki. Może to też być jakiś inny element ze stosu. Co należy zrobić, to usuwać ze stosu kolejne elementy dopóki nie będzie spełniony warunek skrętu w lewo. Przykład "naprawienia własności skrętu w lewo" demonstruje poniższa animacja:
Posiadamy już dostateczną wiedzę, aby zapisać algorytm Grahama w postaci pseudokodu:

Dowodzimy poprawności algorytmu Grahama stosując prostą indukcję przy użyciu następującego niezmiennika pętli zewnętrznej:
Po 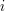 -tej iteracji pętli zewnętrznej punkty
-tej iteracji pętli zewnętrznej punkty ![$ P[1..i] $](/files/tex/efb6fe106e635311488fd0f969c7269e3bb339a2.png) są przetworzone tak, że część z nich należy do stosu , a część nie. Te z nich, które należą do stosu tworzą kolejno łańcuch krawędzi taki, że dla każdej krawędzi, wszystkie inne punkty nienależące do (a będące w ) znajdują się na lewo od niej.
są przetworzone tak, że część z nich należy do stosu , a część nie. Te z nich, które należą do stosu tworzą kolejno łańcuch krawędzi taki, że dla każdej krawędzi, wszystkie inne punkty nienależące do (a będące w ) znajdują się na lewo od niej.
Przed pierwszą iteracją niezmiennik jest zachowany w trywialny sposób. Załóżmy teraz, że jesteśmy po -tej iteracji i przystępujemy do iteracji 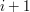 -szej. Zauważmy, że jeśli punkt
-szej. Zauważmy, że jeśli punkt ![$ P[i+1] $](/files/tex/fb8848ed90bdcfc85f70f37e8524ae9834e5a22f.png) psuje własność "skrętu w lewo", to pętla wewnętrzna nam to naprawi. Przy okazji wszystkie punkty, które odrzuci będą znajdowały się na lewo od nowo utworzonej krawędzi. Niezmiennik zostaje zachowany. Gdy pętla się skończy w znajdą się kolejne punkty otoczki wypukłej (na mocy twierdzenia, które udowodniliśmy przy omawianiu algorytmu Jarvisa).
psuje własność "skrętu w lewo", to pętla wewnętrzna nam to naprawi. Przy okazji wszystkie punkty, które odrzuci będą znajdowały się na lewo od nowo utworzonej krawędzi. Niezmiennik zostaje zachowany. Gdy pętla się skończy w znajdą się kolejne punkty otoczki wypukłej (na mocy twierdzenia, które udowodniliśmy przy omawianiu algorytmu Jarvisa).
Nie uwzględniając czasu sortowania mogłoby się wydawać, że algorytm Grahama działa w czasie , gdyż zewnętrzna pętla wykonuje się 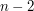 razy, a wewnętrzna pętla może przejść po całym stosie (który maksymalnie może zawierać elementów). Zauważmy jednak, że każdy punkt ze zbioru rozpatrujemy co najwyżej dwa razy - raz gdy zostaje dodany do stosu i raz gdy zostaje usunięty z niego (nie licząc momentów, w których podglądamy wartości dwóch górnych elementów stosu do określenia "skrętu"). Z tego wynika, że właściwa część szukania otoczki wypukłej wykonuje się w czasie
razy, a wewnętrzna pętla może przejść po całym stosie (który maksymalnie może zawierać elementów). Zauważmy jednak, że każdy punkt ze zbioru rozpatrujemy co najwyżej dwa razy - raz gdy zostaje dodany do stosu i raz gdy zostaje usunięty z niego (nie licząc momentów, w których podglądamy wartości dwóch górnych elementów stosu do określenia "skrętu"). Z tego wynika, że właściwa część szukania otoczki wypukłej wykonuje się w czasie 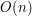 . Jeśli dodamy do tego czas na posortowanie tablicy , to ogólna złożoność wynosi
. Jeśli dodamy do tego czas na posortowanie tablicy , to ogólna złożoność wynosi 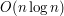 .
.
Jeśli chodzi o algorytm Grahama, to musimy rozpatrzyć taką samą kwestię, jak przy metodzie pakowania prezentu. Chodzi oczywiście o sytuację, gdy trzy punkty są współliniowe. Problem nietrudno jest rozwiązać dodając odpowiedni warunek do pętli wewnętrznej. Popatrzmy na rysunek. Jeśli punkt jest współliniowy z i (i znajduje się dalej od ), to usuwamy, a dodajemy do stosu.
Jednak tutaj należy również pamiętać o jednym skrajnym przypadku. Gdy algorytm się skończy może się okazać, że dwa ostatnio dodane punkty do stosu i punkt startowy są współliniowe (warunek w pętli wewnętrznej tego nie wykryje, bo ostatni rozpatrywany punkt to ![$ P[n] $](/files/tex/ef469e17ab44298036476368eca0fc18121d72fc.png) – nie porównujemy go z ). Po skończeniu działania pętli zewnętrznej należy porównać punkt z dwoma ostatnimi elementami i ostatni element z ewentualnie usunąć.
– nie porównujemy go z ). Po skończeniu działania pętli zewnętrznej należy porównać punkt z dwoma ostatnimi elementami i ostatni element z ewentualnie usunąć.
Do tej pory poznaliśmy dwa algorytmy wyznaczające otoczkę wypukłą na płaszczyźnie i dokładnie je omówiliśmy. Ponadto dokonaliśmy analizy złożoności i udowodniliśmy ich poprawność. Nie musimy się jednak ograniczać tylko do tych dwóch metod. Jak wspomniałem we wstępie, nad problemem otoczki wypukłej pracowało (i dalej pracuje) wielu informatyków.
W ciągu kilkudziesięciu lat powstało mnóstwo różnych algorytmów rozwiązujący ten problem. W tym rozdziale chciałbym przedstawić kilka metod, które pokazują różne podejścia do szukania otoczki. Nie będziemy się wgłębiali zbytnio w te algorytmy. Przedstawiona zostanie tylko ich idea. Zachęcam do przeprowadzenia własnych eksperymentów i badań.
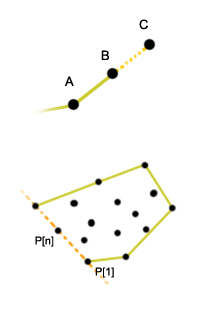
Metoda przyrostowa pokazuje naturalne podejście do rozwiązania problemu otoczki. Wynik będziemy przechowywali na liście podwójnie łączonej (nazwiemy ją oczywiście ). Idea algorytmu jest taka:
Najpierw dodajemy do dwa pierwsze elementy z . Następnie iterujemy po zbiorze ![$ P[3..n] $](/files/tex/03fa5f1704efe5ec79a5fc7f7a8976c9fee27814.png) . Dla każdego punktu ze zbioru sprawdzamy, czy znajduje się wewnątrz wielokąta wypukłego wyznaczonego przez . Jeśli tak: przechodzimy dalej. W przeciwnym wypadku wyznaczamy krawędzie wielokąta , które są widoczne z . Usuwamy te krawędzie i tworzymy nowy wielokąt łącząc z dwoma wolnymi wierzchołkami wielokąta (wolne: czyli takie, które mają tylko jednego sąsiada).
. Dla każdego punktu ze zbioru sprawdzamy, czy znajduje się wewnątrz wielokąta wypukłego wyznaczonego przez . Jeśli tak: przechodzimy dalej. W przeciwnym wypadku wyznaczamy krawędzie wielokąta , które są widoczne z . Usuwamy te krawędzie i tworzymy nowy wielokąt łącząc z dwoma wolnymi wierzchołkami wielokąta (wolne: czyli takie, które mają tylko jednego sąsiada).
Nietrudno zauważyć, że po -tej iteracji jest otoczką wypukłą dla zboru punktów . Każdy nowy punkt po prostu "doczepiamy" do otoczki. Stąd wzięła się nazwa algorytmu, bo otoczka się tak jakby "rozrasta".
Poprawność dowodzimy przez prostą indukcję, więc szczegóły pominiemy. Niestety ta metoda nie jest zbyt efektywna. Jej złożoność to z uwagi na to, że dla każdego punktu z musimy przejść przez całą listę .
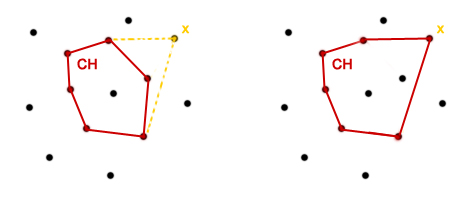
Jeśli znamy algorytm sortowania przez scalanie, to nie będziemy mieli problemu ze zrozumieniem działania algorytmów wyznaczania otoczki wypukłej metodą dziel i zwyciężaj, gdyż w obu przypadkach schemat jest ten sam: rozbijamy problem na dwa pod-problemy, pod-problemy rozwiązujemy rekurencyjnie i rozwiązania pod-problemów scalamy w jedną całość. Ogólną procedurę można by zapisać w taki sposób:

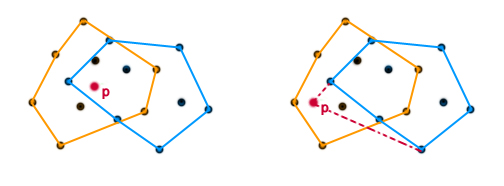
Pozostają pytania: jak dzielić? Jak scalać? Najbardziej intuicyjne byłoby wyznaczenie pionowej prostej dzielącej zbiór na dwa równoliczne zbiory. Następnie osobno dla lewej i prawej części wyznaczalibyśmy otoczkę. Gdyby przyjąć taką wersję, to scalenie dwóch otoczek polega na znalezieniu tzw. krawędzi mostowych. Na rysunku obok oznaczone są kolorem żółtym.
Zauważmy, że dzielenie można zrobić w czasie stałym. Wystarczy wcześniej posortować zbiór i wybrać element środkowy. Scalanie można zaimplementować tak, że będzie działało w czasie , ale to zadnie pozostawię czytelnikowi jako ćwiczenie.
Można spróbować innego podejścia. Załóżmy, że nie chcemy sortować zbioru . W takim wypadku dzielenie jest trywialne: otrzymane podzbiory to po prostu ![$ P[1..\lfloor \frac{n}{2} \rfloor] $](/files/tex/3e45938cfad0b6961038a3685259885a541ed5e0.png) i
i ![$ P[\lceil \frac{n}{2} \rceil ..n] $](/files/tex/291ff047c4451128ca2369c50c7054be0ea8bbb2.png) . Na tych podzbiorach rekurencyjnie szukamy otoczki. Krok scalania będzie jednak bardziej skomplikowany, gdyż otoczki
. Na tych podzbiorach rekurencyjnie szukamy otoczki. Krok scalania będzie jednak bardziej skomplikowany, gdyż otoczki 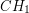 i
i 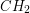 nie muszą być rozłączne (czyli mogą na siebie zachodzić).
nie muszą być rozłączne (czyli mogą na siebie zachodzić).
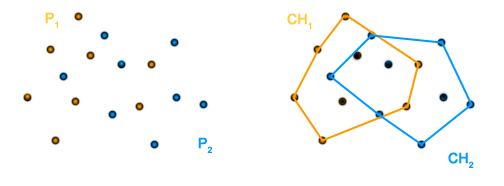
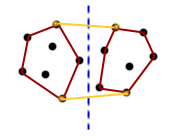
Problem ten można sprytnie rozwiązać: weźmy dowolny punkt leżący wewnątrz otoczki (np. środek ciężkości trójkąta złożonego z trzech dowolnych punktów ). Oznaczmy ten punkt literą . Sprawdzamy, czy punkt leży wewnątrz otoczki . Rozpatrujemy dwa przypadki:
1. Punkt leży wewnątrz . W takim razie prawdą jest, że jest posortowana kątowo względem punktu oraz jest posortowana kątowo względem punktu . Punkty z i można scalić w czasie liniowym tak jakbyśmy to robili przy sortowaniu przez scalanie. Otrzymujemy nowy zbiór punktów 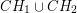 , który jest posortowany względem . Znalezienie otoczki dla tego zbioru jest już łatwe: wystarczy użyć algorytmu Grahama. Sortowanie mamy już z głowy więc cały proces będzie miał złożoność .
, który jest posortowany względem . Znalezienie otoczki dla tego zbioru jest już łatwe: wystarczy użyć algorytmu Grahama. Sortowanie mamy już z głowy więc cały proces będzie miał złożoność .
2. Punkt nie leży wewnątrz . Tutaj sprawa się nieznacznie komplikuje, gdyż nie możemy od razu zrobić prostego scalania. Co prawda jest posortowana kątowo względem , ale (jeszcze) nie. Rozwiązujemy ten problem w następujący sposób: szukamy krawędzie otoczki , które są widoczne z punktu i je usuwamy (tak jakbyśmy to robili w metodzie przyrostowej). I to wszystko. Teraz wystarczy scalić dwa zbiory i użyć algorytmu Grahama.
Która metoda dzielenia i scalania wydaje się być prostsza? To już zależy od osobistych preferencji. W każdym razie złożoność czasowa i tak się nie zmienia. W obu przypadkach wynosi .
Dotychczas zajmowaliśmy się problemem otoczki wypukłej tylko w dwóch wymiarach. Spośród większych wymiarów najbardziej interesujący jest wymiar trzeci. Nie można się nie zgodzić, że otoczka wypukła w trzecim wymiarze posiada duże znaczenie w różnych dziedzinach np. grafice komputerowej.
Na całe szczęście nie trzeba od nowa rozpatrywać naszego problemu tylko dlatego że zwiększyliśmy przestrzeń, w której się poruszamy. Okazuje się, że niektóre algorytmu działające na płaszczyźnie - po drobnych modyfikacjach - nadają się do szukania otoczki wypukłej w 3D (a nawet 4D, 5D itd.). Dla przykładu rozważmy algorytm pakowania prezentu.
Otoczka w trzecim wymiarze będzie wielościanem wypukłym. Na początku załóżmy, że żadne cztery punkty nie leżą na jednej płaszczyźnie. Dzięki temu założeniu uprościmy sobie robotę, bo każda ze ścian otoczki będzie trójkątem. Jak pamiętamy z pierwszej strony: najpierw szukaliśmy punktu startowego. Tym razem będziemy szukali odcinka startowego. Od niego będziemy zaczynali "owijać" zbiór punktów szukając takiego punktu, który wraz z odcinkiem startowym utworzy trójkąt. Poszukiwany przez nas trójkąt musi spełniać taką własność: wszystkie punkty (różne od wierzchołków danego trójkąta) muszą znajdować się po jednej stronie względem tego trójkąta. Dostrzegamy podobieństwo do szukania otoczki w 2D. Trójkąt, który wybraliśmy na pewno należy do otoczki. Powtarzamy krok dla wszystkich odcinków trójkąta, dopóki figura się nie zamknie.
Drugą znaną nam metodą, którą w łatwy sposób można przekształcić jest metoda przyrostowa. Pamiętamy, że w 2D, w każdym następnym kroku wybieraliśmy punkt i szukaliśmy krawędzi otoczki, które są widoczne z tego punktu. Usuwaliśmy te krawędzie i łączyliśmy dany punkt z resztą otoczki. W trzecim wymiarze jest bardzo podobnie: wybieramy punkt i szukamy ścian otoczki, które są widoczne z tego punktu; usuwamy je i dołączamy punkt do reszty otoczki.
O otoczce wypukłej można by dużo opowiadać. Niestety zajęłoby to więcej miejsca niż tych kilka stron. W tym artykule przedstawiłem podstawowe informacje z dziedziny geometrii obliczeniowej, które pomogą początkującym mistrzom algorytmiki w poszerzaniu swoich horyzontów. Na koniec, aby utrwalić poznaną wiedzę, zapraszam do rozwiązania kilku zadań programistycznych.
W pewnym mieście znajduje się wiele sklepików spożywczych, a każdy z nich należy do innej sieci. Jeśli spojrzymy na mapę miasta z lotu ptaka, to łatwo odnajdziemy tzw. strefę wpływów dla danej sieci. Strefę wpływów dla ustalonej sieci definiuje się jako obszar ograniczony przez najmniejszy wielokąt zawierający wszystkie sklepiki sieci A. Innymi słowy, jeśli przyjmiemy, że sklepiki sieci są zbiorem punktów na płaszczyźnie, to jej strefa wpływów jest jej otoczką wypukłą.
Właściciele wszystkich sieci w mieście ustalili, że nie będą sobie wchodzić w drogę i będą tak rozmieszczać swoje sklepy, aby ich strefy wpływów na siebie nie zachodziły.
Pewnego pięknego dnia właściciele spostrzegli, że sklepów spożywczych jest w mieście zbyt wiele przez co konkurencyjność poszczególnych firm spada. Razem ustalili, że połączą się w jedną wielką firmę. Połączeń będą dokonywali stopniowo w określonej kolejności. Każde połączenie zwiększy strefę wpływów.
Tutaj pojawia się problem: po powiększeniu strefy wpływów dwóch kolejnych firm powstaną niepotrzebne sklepy, czyli takie, które leżą wewnątrz (lub na krawędzi) nowej strefy wpływów. Nie mają one wpływu na daną strefę, więc należy je zamknąć.
Na rysunku powyżej najpierw łączymy strefy firm czerwonej i niebieskiej. Zauważmy, że powstały dwa niepotrzebne sklepy. W kolejnym kroku dołączamy strefę zieloną. Wszystkich niepotrzebnych sklepów jest razem pięć.
Twoim zadaniem jest ustalenie łącznej liczby niepotrzebnych sklepów po każdym kroku łączenia dwóch kolejnych firm. Możesz przyjąć następujące założenia:
W pierwszej linii wejścia podana jest liczba 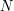 (
(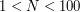 ) oznaczająca liczbę sieci sklepów. Ustalamy, że każda sieć otrzymuje unikalny numer ze zbioru
) oznaczająca liczbę sieci sklepów. Ustalamy, że każda sieć otrzymuje unikalny numer ze zbioru 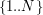 . W kolejnej linii podanych jest liczb oddzielonych spacją, które oznaczają kolejność łączenia stref. Następnie podane są definicje stref. W -tej definicji wyznaczamy strefę -tej sieci. W pierwszej linii definicji podana jest liczba
. W kolejnej linii podanych jest liczb oddzielonych spacją, które oznaczają kolejność łączenia stref. Następnie podane są definicje stref. W -tej definicji wyznaczamy strefę -tej sieci. W pierwszej linii definicji podana jest liczba 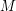 (
(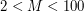 ) oznaczająca liczbę sklepów -tej sieci. W drugiej linii znajduje się
) oznaczająca liczbę sklepów -tej sieci. W drugiej linii znajduje się 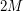 liczb z przedziału
liczb z przedziału ![$ [0,10000] $](/files/tex/48b7fb7a7098aca96333ad18a0475f46574c87af.png) oddzielonych spacjami. Każde kolejnych par liczb wyznacza punkt
oddzielonych spacjami. Każde kolejnych par liczb wyznacza punkt 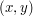 w układzie współrzędnych, który określa położenie sklepu na mapie. Punkty strefy są podane w kolejności przeciwnej do ruchu wskazówek zegara.
w układzie współrzędnych, który określa położenie sklepu na mapie. Punkty strefy są podane w kolejności przeciwnej do ruchu wskazówek zegara.
Wyjście składa się z jednej linii. Należy wypisać 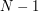 liczb oddzielonych spacjami. Każda z nich oznacza liczbę niepotrzebnych sklepów po połączeniu dwóch kolejnych stref zgodnie z kolejnością podaną na wejściu.
liczb oddzielonych spacjami. Każda z nich oznacza liczbę niepotrzebnych sklepów po połączeniu dwóch kolejnych stref zgodnie z kolejnością podaną na wejściu.
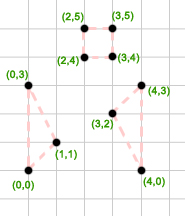
Wejście:
3
1 2 3
3
0 0 1 1 0 3
3
3 2 1 0 4 3
4
2 4 3 4 3 5 2 5
Wyjście:
2 4
Odnośniki:
[1] http://informatyka.wroc.pl/node/455
[2] http://informatyka.wroc.pl/user
[3] http://informatyka.wroc.pl/user/register