
Na zajęciach poznaliśmy też inną struktruę danych, która posiada "explicit layout", jaką jest union-find, zaimplementowany jako pojedyncza tablica.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | int u[N]; int find(int x); bool unite(int x,int y){ x=find(x); y=find(y); if(x==y)return false; if(u[x]<u[y]){ u[y]=x; }else if(u[y]<u[x]){ u[x]=y; }else{ u[x]=y; --u[y]; } return true; } memset(u,-1,sizeof(u)); |
Tu dygresja jest taka, że memset jako drugi argument bierze pojedynczy bajt, więc to, że ten kod działa wynika tylko z tego, że czterobajtowy zapis liczby -1, wygląda tak samo jak 4 zapisy jednobajtowej liczby -1 pod rząd.
Jako ćwiczenie można sobie zaimplementować funkcję find.
|
|
Napisz funkcję
| ||
|
| |||
Oto jedno z moich ulubionych zadanek pochodzące z 10 Olimpiady Informatycznej Małpki [1]. Zadanko jest dostępne na MAINie SIO [2].
Powiedzieliśmy sobie też, z grubsza co to jest logartym iterowany, oraz, że analiza złożoności dla problemu Union-Find do najłatwiejszych nie należy. Kluczowe jednak są pewne prawdy objawione:
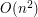 , chociaż program nadal będzie działał
, chociaż program nadal będzie działałPrawda jest taka, że Union-Find działa bardzo szybko i że nie chodzi nawet o logarytm iterowany, tylko o odwrotność funkcji Ackermana. Prawda jest też taka, że żeby móc coś sensownie mówić o złożoności, to wypada powiedzieć ile operacji union, a ile operacji find, chcemy zrobić. Nie mniej, do naszych ziemskich celów, wystarczy wiedzieć, że to jest po prostu mniej niż 4.
Odnośniki:
[1] http://www.oi.edu.pl/html/zadania/oi10/tex/malzad.pdf
[2] http://www.main.edu.pl/user.phtml?op=showtask&task=mal&con=OI10
[3] http://en.wikipedia.org/wiki/Disjoint-set_data_structure