
Algorytm, który wyznacza najdłuższy wspólny podciąg (z ang. LCS - Longest Common Subsequence) dwóch wyrazów, jest eleganckim przykładem potęgi programowania dynamicznego. Rozwiązanie konstruowane jest stopniowo - zaczynamy od mniejszych (zatem łatwiejszych) podproblemów. Wyniki dla nich pozwolą nam na zgrabne utworzenie odpowiedzi dla pierwotnego zadania.
Jeśli jakieś pojęcia w tym tekście wydadzą ci się niejasne, zawsze możesz zajrzeć do artykułu o podstawach algorytmów tekstowych [1].
Przez większość tego tekstu będziemy starali się rozwiązać jeden problem, wypada zatem opisać go w ścisły i jednoznaczny sposób. Aby to uczynić wprowadźmy najpierw następujące pojęcie:
Niech 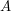 i
i 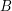 będą dwoma wyrazami (czyli ciągami liter, zakładamy to dla wygody - w rzeczywistości mogą to być dowolne ciągi). Mówimy, że jest podciągiem wtedy i tylko wtedy, gdy istnieje taki rosnący ciąg liczb naturalnych
będą dwoma wyrazami (czyli ciągami liter, zakładamy to dla wygody - w rzeczywistości mogą to być dowolne ciągi). Mówimy, że jest podciągiem wtedy i tylko wtedy, gdy istnieje taki rosnący ciąg liczb naturalnych 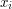 , że zachodzi:
, że zachodzi:
![$ A[i] = B[x_i] $](/files/tex/7d367a67bf492f50e74a396646ec8e5b6a410922.png) dla wszystkich
dla wszystkich 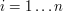 , gdzie
, gdzie  to długość wyrazu , a
to długość wyrazu , a ![$ A[i] $](/files/tex/89cb51e6ef76ddca2565e0a10a07a43654a45ca1.png) oznacza i-tą literkę z .
oznacza i-tą literkę z .
Czyli, w prostszych słowach, jest podciągiem , jeśli potrafimy tak wybierać z kolejne literki, aby utworzyć wyraz .

Teraz możemy w końcu zdefiniować problem przewodni tego artykułu:
Dla danych dwóch wyrazów 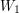 i
i 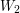 należy znaleźć najdłuższy taki wyraz
należy znaleźć najdłuższy taki wyraz 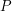 , aby był podciągiem i podciągiem .
, aby był podciągiem i podciągiem .

Zdefiniujmy najpierw jeszcze jedno pomocnicze pojęcie:
Niech 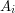 będzie wyrazem złożonym z pierwszych
będzie wyrazem złożonym z pierwszych 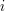 liter . nazywamy prefiksem słowa .
liter . nazywamy prefiksem słowa . 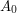 uznawać będziemy za wyraz złożony z zera liter (czyli słowo puste).
uznawać będziemy za wyraz złożony z zera liter (czyli słowo puste).
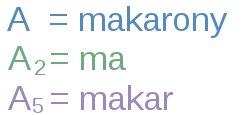
Optymalny algorytm będzie wprost wynikał z dwóch prostych obserwacji.
Załóżmy, że znamy długość najdłuższego wspólnego podciągu dla par prefiksów:
i 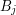 ,
,
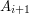 i ,
i
i ,
i 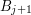 .
.
Na podstawie powyższych informacji spróbujemy teraz wyliczyć długość LCS dla i . Rozpatrzymy dwa przypadki:
a) Jeśli ![$ A[i+1]=x $](/files/tex/f1ccc3e72c336c71c2654a43ba030de37a5ff7ae.png) i
i ![$ B[j+1]=x $](/files/tex/b94723e98a2c23d08c8266f1b842ca156696b61f.png) to LCS dla tych dwóch wyrazów może zostać utworzony poprzez dodanie literki
to LCS dla tych dwóch wyrazów może zostać utworzony poprzez dodanie literki  na koniec LCS dla wyrazów i . Dlaczego? Gdyby w najdłuższym wspólnym podciągu i nie było literki na końcu, moglibyśmy go przedłużyć, dokładając doń ostatnią literkę i (czyli właśnie tego ). Ale wtedy powstałby podciąg dłuższy od najdłuższego! Literka musi być więc ostatnią literką każdego poprawnie wyliczonego LCS. Najmniej "utracimy" zatem jeśli źródłem literki będą końce i - pozostanie wtenczas jeszcze literek prefiksu i
na koniec LCS dla wyrazów i . Dlaczego? Gdyby w najdłuższym wspólnym podciągu i nie było literki na końcu, moglibyśmy go przedłużyć, dokładając doń ostatnią literkę i (czyli właśnie tego ). Ale wtedy powstałby podciąg dłuższy od najdłuższego! Literka musi być więc ostatnią literką każdego poprawnie wyliczonego LCS. Najmniej "utracimy" zatem jeśli źródłem literki będą końce i - pozostanie wtenczas jeszcze literek prefiksu i 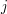 literek prefiksu i z nich tworzyć będziemy resztę najdłuższego wspólnego podciągu.
literek prefiksu i z nich tworzyć będziemy resztę najdłuższego wspólnego podciągu.

b) Jeśli a ![$ B[j+1]=y $](/files/tex/1d7ab4161c1b1fc862295e2f649a7c23c65cb5c3.png) i
i 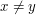 , to LCS dla i jest też LCS dla co najmniej jednej z dwóch par:
, to LCS dla i jest też LCS dla co najmniej jednej z dwóch par: 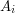 i lub i
i lub i 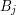 . Skąd taki wniosek? Ostatnią literką najdłuższego wspólnego podciągu dla i nie mogą być jednocześnie i
. Skąd taki wniosek? Ostatnią literką najdłuższego wspólnego podciągu dla i nie mogą być jednocześnie i 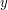 (bo to dwie różne literki). Zatem jeden z wyrazów i możemy bez żadnej straty pozbawić jego ostatniej literki. Nie wiemy jednak który z nich, zatem zwyczajnie sprawdzimy obie możliwości i wybierzemy tę, która daje lepszy wynik.
(bo to dwie różne literki). Zatem jeden z wyrazów i możemy bez żadnej straty pozbawić jego ostatniej literki. Nie wiemy jednak który z nich, zatem zwyczajnie sprawdzimy obie możliwości i wybierzemy tę, która daje lepszy wynik.

Czyli możemy z pewnością stwierdzić, że 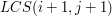 (tak będziemy od teraz oznaczać długość LCS dla pary , ) to:
(tak będziemy od teraz oznaczać długość LCS dla pary , ) to:
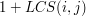 , jeśli
, jeśli ![$ A[i+1]=B[j+1] $](/files/tex/caac3343855e9150a0541a2135773f1b60db397f.png) (przypadek a),
(przypadek a),
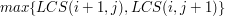 , jeśli
, jeśli ![$ A[i+1] \neq B[j+1] $](/files/tex/5f30087b614dc42aef75e1a891d5a8790c0ecda7.png) (przypadek b).
(przypadek b).
LCS dla i zawsze składa się z zera literek. Jest to dość oczywiste - w nie ma żadnej literki, więc nic dłuższego niż słowo puste nie może być podciągiem . Analogicznie: LCS dla i 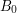 też ma zawsze zero literek. Prawdziwe są zatem następujące równości:
też ma zawsze zero literek. Prawdziwe są zatem następujące równości:
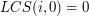 dla każdego naturalnego
dla każdego naturalnego
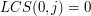 dla każdego naturalnego
dla każdego naturalnego
Jeśli poniższy opis wyda ci się niejasny, możesz spojrzeć na szóstą stronę tego tekstu, gdzie znajduje się przykład działania algorytmu na dwóch konkretnych wyrazach.
Jeśli liczby i 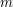 są długościami odpowiednio i , to z pewnością
są długościami odpowiednio i , to z pewnością 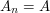 i
i 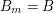 . Wtedy
. Wtedy 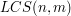 oznacza długość najdłuższego wspólnego podciągu dla całych wyrazów i . Aby wyliczyć tę wartość, utworzymy tablicę o wymiarach
oznacza długość najdłuższego wspólnego podciągu dla całych wyrazów i . Aby wyliczyć tę wartość, utworzymy tablicę o wymiarach 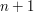 na
na 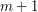 komórek, bowiem w komórce
komórek, bowiem w komórce 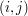 chcemy przechowywać liczbę
chcemy przechowywać liczbę 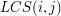 (dla
(dla 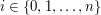 oraz
oraz 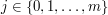 ). Druga obserwacja pozwoli nam na wpisanie do tej tablicy pewnej liczby początkowych wartości, wzór z obserwacji pierwszej posłuży do dalszego wypełniania komórek.
). Druga obserwacja pozwoli nam na wpisanie do tej tablicy pewnej liczby początkowych wartości, wzór z obserwacji pierwszej posłuży do dalszego wypełniania komórek.

 .
.
Skoro prawdą jest, że i , to zerowy wiersz i zerową kolumnę tabeli wypełnić należy zerami.

Teraz zajmiemy się dalszym uzupełnianiem tabeli. Będziemy wyliczać wartości w kolejnych wierszach, idąc od lewej do prawej. Dzięki temu w chwili, gdy przyjdzie nam ustalać wartość w komórce , wszystkie potrzebne nam do tego komórki będą już poprawnie wypełnione. Z obserwacji pierwszej wynika bowiem, że wartość w zależeć może jedynie od trzech komórek: 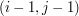 ,
, 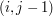 ,
, 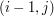 .
.

Jak wyliczamy wartość w polu ? Jeśli ![$ A[i]=B[j] $](/files/tex/3db538d9ca4640dd8802547b0069ddc11f3a8a20.png) , to zgodnie ze wzorem z obserwacji pierszej musimy dodać jeden do . Jeśli jednak
, to zgodnie ze wzorem z obserwacji pierszej musimy dodać jeden do . Jeśli jednak ![$ A[i] \neq B[j] $](/files/tex/c091a466653a32786bcb3d99ab45b48869175097.png) , to w wpisujemy większą z liczb znajdujących się w komórkach i .
, to w wpisujemy większą z liczb znajdujących się w komórkach i .


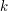 i , czyli większą z wartości z pól sąsiadujących z danym polem z lewej strony i z góry.
i , czyli większą z wartości z pól sąsiadujących z danym polem z lewej strony i z góry.
Wypełniamy w ten sposób całą tablicę i w polu 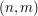 otrzymujemy długość najdłuższego wspólnego podciągu dla wyrazów i . Jeśli interesowała nas jedynie ta wartość, to możemy zakończyć pracę. Coż jednak mamy zrobić, jeśli nie chcemy znać tylko długości LCS dla tych wyrazów, ale także i to, jaką ten podciąg ma postać? Na szczęście z łatwością możemy odtworzyć jego wygląd, wszystko dzięki wypełnionej już tablicy!
otrzymujemy długość najdłuższego wspólnego podciągu dla wyrazów i . Jeśli interesowała nas jedynie ta wartość, to możemy zakończyć pracę. Coż jednak mamy zrobić, jeśli nie chcemy znać tylko długości LCS dla tych wyrazów, ale także i to, jaką ten podciąg ma postać? Na szczęście z łatwością możemy odtworzyć jego wygląd, wszystko dzięki wypełnionej już tablicy!
Wyobraźmy sobie, że w każdej komórce tablicy poza liczbą znajduje się też i strzałka, która wskazuje na pole zawierające tę wartość, która była nam potrzebna przy wyliczaniu liczby w . Zauważmy, że jeśli to strzałka w będzie skierowana na skos, a jeśli , to w górę lub w lewo - zależnie od tego, gdzie będzie większa wartość (w przypadku remisu kierunek strzałki jest dowolny).
Strzałka skośna odpowiada "przedłużaniu" LCS o ostatnią literkę obu rozpatrywanych prefiksów (przypadek "a" z obserwacji pierwszej).
Strzałki w lewo i w górę odpowiadają następującej decyzji: czy dłuższym podciągiem i będzie LCS i , czy może LCS i ?
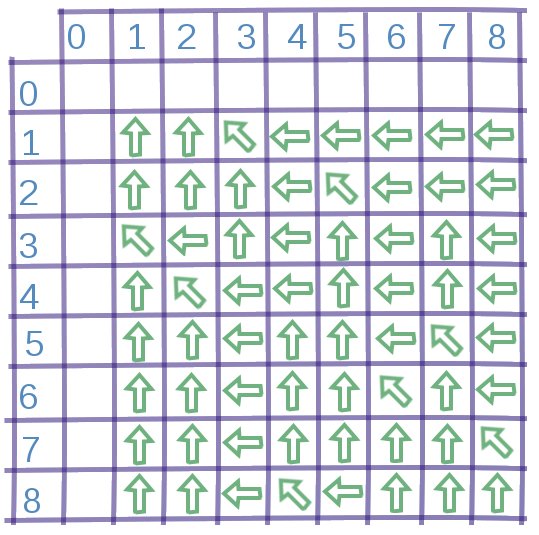
Aby odtworzyć LCS musimy przejść zgodnie ze strzałkami z pola do lewej bądź górnej krawędzi tablicy. Za każdym razem, gdy pójdziemy na skos, znajdujemy kolejną literkę z LCS. W związku z tym, że cała tablica jest już wypełniona wartościami , strzałki wskazują zawsze ten wybór, który prowadzi do najdłuższego podciągu. Jeśli więc natrafimy na strzałkę skośną w polu 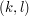 , oznacza to, że najlepiej będzie jako kolejną literkę odtwarzanego LCS wybrać
, oznacza to, że najlepiej będzie jako kolejną literkę odtwarzanego LCS wybrać ![$ A[k] = x $](/files/tex/20d0fdbe4ad43b963f0c06881f9c2c9c908c7580.png) (zachodzi też
(zachodzi też ![$ x = B[l] $](/files/tex/171efe3a5b22dc0e17a460064468c313e4bbe211.png) , bo tylko w takiej sytuacji mogliśmy natrafić na strzałkę na skos). Pamiętajmy jednak, że odtwarzamy LCS od końca!
, bo tylko w takiej sytuacji mogliśmy natrafić na strzałkę na skos). Pamiętajmy jednak, że odtwarzamy LCS od końca!
Oczywiście nie musimy uwzględniać żadnych strzałek w naszym kodzie. Wystarczy bowiem kilka porównań, aby sprawdzić w którą stroną skierowana by była strzałka w danym polu. Jeśli , to w polu znajdowałaby się strzałka na skos. W przeciwnym wypadku musimy sprawdzić w którym z pól czy wpisana jest większa wartość - na to pole wskazywałaby strzałka z komórki .
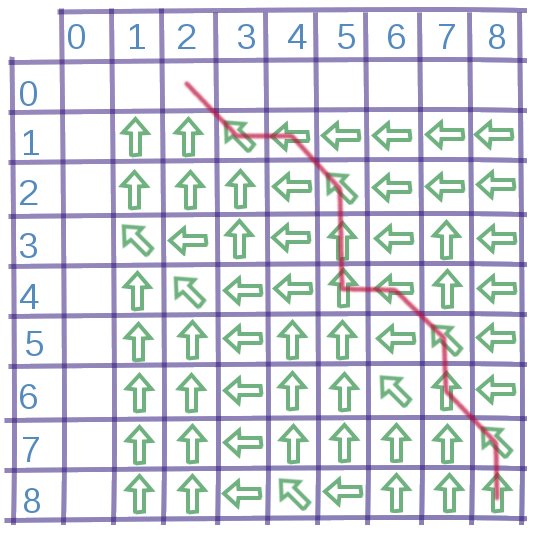
Aby przekonać się o tym, że algorytm jest naprawdę bardzo prosty, wyznaczmy za jego pomocą LCS dla wyrazów "markotny" i "romantyk".
Najpierw tworzymy tablicę 9x9 (długość pierwszego słowa + 1 na długość drugiego słowa + 1) i wypełniamy zerowy wiersz i zerową kolumnę zerami.

Wypełniamy resztę pól tablicy. Wyliczamy wartości dla kolejnych wierszy, idąc od lewej do prawej. Jeśli jakiemuś polu odpowiadają różne literki w obu wyrazach, to wpisujemy weń większą z liczb z pól nad nim i po lewej. Jeśli zaś rozpatrywane pole odpowiada tym samym literkom, to wpisujemy do niego zwiększoną o jeden liczbę z pola "na skos" (w lewo i do góry).

Teraz będziemy odtwarzać wyznaczony podciąg. Zaczynamy od pola (9,9) i "cofamy" się aż do lewej lub górnej krawędzi. Jeśli pole odpowiada różnym literkom, to "idziemy" do pola po lewej lub w górę - decyzja zależy od tego, w którym znajduje się większa liczba. W przypadku gdy polu odpowiadają te same literki w obu słowach idziemy na skos (znów w lewo i do góry) i zapisujemy sobie gdzieś, że znaleźliśmy następną literkę wyznaczonego LCS. Gdy dotrzemy do lewej/górnej krawędzi, znamy już cały najdłuższy wspólny podciąg wyrazów "markotny" i "romantyk" - jest to wyraz "rony".

Jeśli przyjrzymy się powyższemy przykładowi, to zauważymy, że jeśli zależy nam jedynie na wyliczeniu długości LCS, to o dużej ilości wierszy wypełnianej tablicy możemy "zapominać". Do wyliczenia wartości w dowolnej komórce z i-tego wiersza potrzebujemy bowiem jedynie informacji o liczbach z komórek leżących bezpośrednio na lewo, w górę i na skos od niego. Wszystkie one znajdują się w wierszach o numerach i-1 oraz i. Zatem to, jakie wartości znajdują się w wierszach od 0 do i-2 jest już kompletnie bezużyteczną informacją! Możemy więc ograniczyć się do przechowywania jedynie poprzedniego wiersza i tego, który aktualnie wypełniamy. Dzięki temu zmniejszamy zużycie pamięci - nie potrzebujemy już  komórek tablicy, wystarczy ich nam
komórek tablicy, wystarczy ich nam 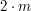 . Gdy wypełnimy jakiś wiersz, to on staje się nowym "poprzednim wierszem", a my na jego podstawie wyliczamy wartości w kolejnym. Gdy skończymy, w pamięci znajdować się będą dwa wiersze - ostatni i przedostatni. Na końcu ostatniego wiersza odnajdziemy liczbę będącą długością LCS. Oczywiście nie ma nic za darmo, teraz nie uda się nam już odtworzyć postaci LCS poprzez wędrowanie po tablicy.
. Gdy wypełnimy jakiś wiersz, to on staje się nowym "poprzednim wierszem", a my na jego podstawie wyliczamy wartości w kolejnym. Gdy skończymy, w pamięci znajdować się będą dwa wiersze - ostatni i przedostatni. Na końcu ostatniego wiersza odnajdziemy liczbę będącą długością LCS. Oczywiście nie ma nic za darmo, teraz nie uda się nam już odtworzyć postaci LCS poprzez wędrowanie po tablicy.
Możliwe jest jeszcze bardziej oszczędne wyliczanie LCS - wystarczy bowiem jeden wiersz. Czy widzisz jak należałoby nadpisywać w nim wartości z poprzedniego wiesza liczbami wyliczonymi dla następnego? Przeanalizuj ponownie działanie algorytmu i zwróć uwagę na to, jak długo potrzebujemy kolejnych wartości z początkowych komórek poprzedniego wiersza.
Na następnej stronie znajdują się dwa zadania programistyczne, które pomogą w sprawdzeniu zrozumienia powyższego algorytmu. Z całego serca polecam rozwiązanie choć jednego z nich.
Czy potrafisz szybko odpowiadać na wiele pytań o najdłuższy wspólny podciąg pary dowolnych prefiksów wyrazów i ?
Pierwszy wiersz wejścia zawiera ciąg znaków (małe i duże litery alfabetu łacińskiego oraz cyfry 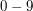 ) będący wyrazem , o którym wiemy, że jego długość nie przekracza
) będący wyrazem , o którym wiemy, że jego długość nie przekracza 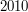 .
.
W wierszu drugim znajduje się ciąg liter będący słowem , który również spełnia wszystkie powyższe ograniczenia.
Trzeci wiersz zawiera jedną liczbę naturalną .
W każdej z kolejnych linijek znajdują się takie dwie nieujemne liczby całkowite 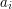 i
i 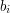 , że długość jest nie większa niż , a długość nie większa niż .
, że długość jest nie większa niż , a długość nie większa niż .
Dla każdej pary liczb i należy wypisać najdłuższy podciąg wyrazów 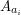 i
i 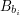 (gdzie
(gdzie 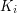 to wyraz będący pierwszymi literkami wyrazu
to wyraz będący pierwszymi literkami wyrazu 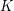 ). Jeśli istnieje wiele podciągów o największej długości, to wypisz dowolny z nich. Jeśli LCS będzie miał długość 0 (czyli będzie słowem pustym), to zamiast niego wypisz znak !.
). Jeśli istnieje wiele podciągów o największej długości, to wypisz dowolny z nich. Jeśli LCS będzie miał długość 0 (czyli będzie słowem pustym), to zamiast niego wypisz znak !.
Dla wejścia:
cdcddbdadbcdbdbddada
ddcdddaaccd
10
5 5
18 7
3 8
10 5
1 4
14 7
9 1
12 6
12 9
1 1
Poprawnym wyjściem będzie:
dcdd
ddcddda
dc
dddd
c
dcddda
d
ddddd
dcdddac
!
W tym zadaniu należy jedynie znaleźć długość LCS dla dwóch podanych na wejściu wyrazów. Limit pamięci jest jednakże niewielki, dlatego postaraj się ograniczyć jej zużycie.
Wejście składa się z dwóch wierszy. W każdym znajduje się niepusty ciąg znaków (małe litery alfabetu łacińskiego) o długości mniejszej niż 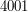 . Pierwszy wiersz zawiera wyraz , drugi - .
. Pierwszy wiersz zawiera wyraz , drugi - .
Należy wypisać jedną nieujemną liczbę całkowitą równą długości najdłuższego wspólnego podciągu wyrazów i .
Dla wejścia:
dcbbaacbda
dacddaadaabbcbb
Poprawnym wyjściem będzie:
6
Odnośniki:
[1] http://informatyka.wroc.pl/node/399
[2] http://informatyka.wroc.pl/user
[3] http://informatyka.wroc.pl/user/register