
W poprzednim artykule [1] dowiedzieliśmy się, jak pisać programy równoległe w Erlangu przy użyciu procesów i wymiany komunikatów. Rozwiniemy teraz tę wiedzę i nauczymy się, jak radzić sobie z błędami, jak wymieniać kod pracującego programu bez przerywania go i w jaki sposób uruchamiać procesy na zdalnych komputerach.
Na poziomie procesów język Erlang posiada dość konwencjonalny mechanizm obsługi błędów oparty na wyjątkach. Informacja o błędzie - na przykład dzieleniu przez zero, nieprawidłowym dopasowaniu wzorca, czy też błędzie zgłoszonym przez programistę za pomocą instrukcji throw, jest propagowana wyżej, do momentu, aż zostanie obsłużona przez instrukcję catch lub try. Błąd nie obsłużony kończy działanie procesu.
Instrukcja try ma następującą postać:
throw(Term)
Komunikat o błędzie Term może być dowolnym termem. Podobnie, jak w przypadku komunikatów, najczęściej jako komunikatu o błędzie używa się krotki, której pierwszy element jest atomem oznaczającym rodzaj błędu - na przykład {blad_pliku, "Plik nie istnieje"}.
Prostą metodą obsługi błędów jest instrukcja catch. Wyrażenie postaci catch wyrażenie oblicza się do wartości wyrażenia wewnętrznego, jeśli te wykona się bez błędów, w przeciwnym wypadku wynikiem jest komunikat błedu. Przykładowo, następujące wyrażenie:
catch 2+2
Oblicza się do wartości 4, zaś takie wyrażenie:
catch 2+throw(blad)
Oblicza się do atomu blad.
|
|
Eksperymentuj! Napisz na przykład catch 1/0. albo catch a=b. (jak zwykle pamiętając o kropce na końcu!)
|
|
| |
Z instrukcji catch nie korzysta się zbyt często, ponieważ jest kłopotliwa w użyciu. Częściej używaną, bo i bardziej wszechstronną, jest instrukcja try, pozwalająca obsłużyć konkretny rodzaj błędu określony za pomocą wzorca. Komunikaty błędów, które nie dopasowały się do żadnego wzorca, nie są przechwytywane przez instrukcję try. Domyślnie instrukcja try przechwytuje tylko błędy wywołane przez instrukcję throw. Dla przykładu, w poniższym kodzie:
test(X) ->
try
if
X == 0 -> throw(zero);
true -> 1/X
end
catch
zero -> 42
end.
Jeśli X było różne od zera, wynikiem jest liczba odwrotna, w przeciwnym wypadku wynikiem jest 42.
Za pomocą instrukcji try można, podobnie jak za pomocą catch, przechwytywać błędy wykonania programu. Powyższy program można lepiej zapisać w taki sposób:
test(X) -> try
try
1/X
catch
error:badarith -> 42
end.
Jak widać, dzielenie przez 0 wywołuje błąd badarith. Najczęściej występujące rodzaje błędów to:
badarg - nieprawidłowy argument funkcji, na przykład spawn(1).badarith - błąd w obliczeniach, na przykład 1/0.{badmatch, V} - wartość V nie została dopasowana do wzorca przy instrukcji przypisania, na przykład {a, X} = {b, 1}.function_clause - żadna z klauzul definiujących funkcję nie została dopasowana.{case_clause, V} - wartość V nie została dopasowana do żadnego ze wzorców instrukcji case.|
|
Napisz funkcję test(X), która wywołuje funkcję bledna(X) i zwraca wartość {ok, bledna(X)}, jeśli funkcja bledna wykona się bez błędów, wartość {throw, Blad} jeśli funkcja bledna wywołała throw(Blad), zaś {error, Blad}, jeśli nastąpi błąd wykonania Blad.
|
|
| |
Co się dzieje, gdy błąd nie zostanie przechwycony przez żadną instrukcję catch ani try? Jak wspomniałem wcześniej, proces, który wywołał błąd, kończy pracę. Nie jest to najczęściej dobry pomysł, gdyż zakończony proces mógł komunikować się z innymi procesami - a inne procesy, nieświadome awarii swojego partnera, mogą niepotrzebnie długo czekać na komunikaty, które nigdy nie nadejdą. W związku z tym w Erlangu istnieje dodatkowy mechanizm pozwalający procesom informować inne procesy o swojej awarii - tak zwane powiązania. Procesy powiązane ze sobą w wyniku błędu kończą działanie wspólnie - jeśli w jednym z procesów nastąpi błąd, kończą działanie wszystkie z nich.
Znając identyfikator innego procesu Pid, proces może utworzyć z nim powiązanie za pomocą funkcji link(Pid). Można też utworzyć powiązanie z nowym procesem w momencie jego tworzenia, używając funkcji spawn_link zamiast omówionej wcześniej spawn. Powiązanie usuwa się funkcją unlink(Pid).
Usuwanie powiązanych procesów w wypadku błędu jest najczęściej dobrą strategią - jeśli procesy blisko współpracowały ze sobą, awaria jednego z nich najczęściej uniemożliwi zakończenie pracy wszystkim! W niektórych sytuacjach lepiej jest jednak, aby powiązanego procesu nie usuwać, ale żeby mimo wszystko wiedział on o awarii swojego partnera - na przykład po to, aby uruchomić go ponownie. Można wtedy wywołać następującą funkcję:
process_flag(trap_exit, true)
Instrukcja ta powoduje, że w przypadku awarii powiązanego procesu aktualny proces nie zakończy działania, za to otrzyma komunikat postaci {'EXIT', Pid, Blad}, gdzie Pid jest identyfikatorem procesu kończącego działanie, a Blad - komunikatem błędu, który spowodował jego zakończenie. Proces działający w ten sposób nazywamy przechwytującym komunikaty o wyjściu. A oto przykładowy program, działający podobnie do poprzednich:
test(X) ->
process_flag(trap_exit, true),
Self = self(),
Pid = spawn_link(fun () -> Self ! {ok, X/0} end),
receive
{ok, A} -> A;
{'EXIT', Pid, {badarith, _}} -> A
end.
Na koniec wspomnę jeszcze o funkcji exit(Pid, Blad). Wykonanie tej funkcji daje efekt analogiczny do awarii procesu powiązanego z procesem Pid - proces ten kończy działanie lub otrzymuje komunikat EXIT, w zależności od tego, czy przechwytuje komunikaty o wyjściu, czy nie. Jeśli jako Blad poda się kill, proces Pid zostanie zakończony nawet wtedy, gdy przechwytuje komunikaty o wyjściu.
Jedną z bardziej interesujących cech Erlanga jest możliwość wymiany kodu programu w trakcie jego pracy. Mechanizm ten jest bardzo istotny z praktycznego punktu widzenia - zdolność poprawienia błędów lub wprowadzenia nowej funkcjonalności do programu bez tworzenia widocznej przerwy w jego pracy jest bardzo ważna, jeśli program ten pracuje 24 godziny na dobę i cały czas obsługuje klientów! W Erlangu osiągnięcie tego jest nietrudne.
Oto prosty program zawierający funkcję tworzącą proces i komunikującą się z nim:
-module(pingpong).
-export([mkpingpong/0,pingpong/1,ping/1]).
pingpong(X) ->
receive
{ping, Pid} -> Pid ! {pong, X}
end,
pingpong:pingpong(X).
mkpingpong() ->
spawn(fun () -> pingpong(0) end).
ping(Pid) ->
Pid ! {ping, self()},
receive
{pong, X} -> X
end.
Nowe dla nas są linijki -module i -export. Są one związane z mechanizmem modułów w Erlangu - czyli sposobem dzielenia programu na mniejsze, niezależne fragmenty. Linijka -module wprowadza nazwę modułu, za pomocą której będziemy się do niego odwoływać: jeśli z innego modułu zechcemy wywołać funkcję zawartą w module pingpong, poprzedzimy nazwę funkcji napisem pingpong:, na przykład pingpong:mkpingpong. Linijka -export natomiast wymienia, jakie funkcje będą dostępne na zewnątrz modułu. Ponieważ możliwe jest istnienie kilku funkcji z tą samą nazwą, lecz z różną liczbą argumentów, po nazwie funkcji podajemy jej liczbę argumentów - na przykład pingpong/1.
Dziwnym może wydawać się, że rekurencyjne wywołanie w funkcji pingpong napisałem przez odwołanie się do modułu. Przecież po zastąpieniu linijki pingpong:pingpong(X) przez pingpong(X) powinniśmy dostać tak samo działający program! To prawda, ale nie do końca, co niedługo się okaże.
Zapiszmy powyższy program w pliku pingpong.erl, po czym uruchommy interpreter Erlanga erl:
$ erl Erlang R13B01 (erts-5.7.2) [source] [rq:1] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.7.2 (abort with ^G) 1>
Aby załadować właśnie napisany moduł, napiszmy w interpreterze c(pingpong):
1> c(pingpong).
{ok,pingpong}
2>
Za pomocą funkcji pingpong:mkpingpong możemy utworzyć nowy proces, a następnie wysłać do niego komunikat za pomocą pingpong:ping:
2> Pid = pingpong:mkpingpong(). <0.42.0> 3> pingpong:ping(Pid). 0 4> pingpong:ping(Pid). 0 5>
Działa! Po chwili zastanowienia jednak stwierdzamy, że chcielibyśmy, żeby kolejne wywołania funkcji ping dawały coraz większe wyniki. Moglibyśmy teraz zatrzymać interpreter, zmienić program, po czym powtórzyć wszystko od nowa, jak to robi się zazwyczaj. My jednak zrobimy inaczej. Nie wyłączając interpretera zmieńmy linijkę z wywołaniem rekurencyjnym w funkcji pingpong na:
pingpong:pingpong(X+1).
Wróćmy do interpretera. Załadujmy moduł po raz kolejny:
5> c(pingpong).
{ok,pingpong}
6>
Ponieważ nie wyłączaliśmy interpretera, proces o identyfikatorze Pid powinien wciąż pracować. Zobaczmy, co się stanie, jak użyjemy funkcji ping:
6> pingpong:ping(Pid). 0 7> pingpong:ping(Pid). 0 8> pingpong:ping(Pid). 1 9> pingpong:ping(Pid). 2 10>
A-ha! Zaczęliśmy dostawać coraz większe wyniki - czyli wcześniej uruchomiony przez nas proces zaczął wykonywać nowy kod! W którym momencie to nastąpiło? Naturalnie - w momencie rekurencyjnego wywołania w funkcji pingpong:
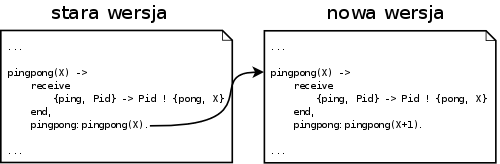
Podanie nazwy modułu przy tym wywołaniu było kluczowe - bez niego wymiana kodu nie mogłaby nastąpić!
Potrafimy już uruchamiać równolegle pracujące procesy na jednym komputerze. Czasem jednak dobrze jest, aby różne procesy jednego programu pracowały na różnych komputerach - na przykład dlatego, że pojedynczy komputer nie ma wystarczającej wydajności, albo jeśli potrzebne zasoby (pliki, urządzenia...) znajdują się na różnych komputerach. Dzięki temu, że procesy w Erlangu nie współdzielą pamięci, w języku tym możliwe jest komunikowanie się ze zdalnym procesem tak samo wygodnie, jak z procesem lokalnym.
Na początek przygotujmy środowisko pracy. Przyjmijmy, że posiadamy dwa komputery, nazywające się kerulen i sungari, z prawidłowo skonfigurowanymi nazwami w DNS albo wpisanymi do pliku hosts. Uruchommy na obydwu komputerach interpreter za pomocą polecenia:
erl -sname test -setcookie abcdef
Opcja -sname ustala nazwę, pod jaką będzie funkcjonować w sieci właśnie uruchamiana instancja interpretera. Na jednym komputerze może pracować i komunikować się ze sobą kilka różnych instancji interpretera o różnych nazwach. (Istnieje również opcja -name, która różni się tylko tym, że identyfikatorem komputera staje się pełna nazwa komputera w DNS, np. kerulen.test.pl, zamiast kerulen.) Natomiast opcja -setcookie ustala ciasteczko - ciąg znaków, który musi być identyczny na wszystkich komunikujących się komputerach. Jest to prosta forma zabezpieczenia przed wdarciem się agresora do sieci komunikujących się interpreterów.
Na komputerze kerulen interpreter zgłosi się na przykład tak:
$ erl -sname test -setcookie abcdef Erlang R13B02 (erts-5.7.3) [source] [rq:1] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.7.3 (abort with ^G) (test@kerulen)1>
Natomiast na sungari odpowie następująco:
$ erl -sname test -setcookie abcdef Erlang R13B02 (erts-5.7.3) [source] [rq:1] [async-threads:0] [hipe] [kernel-poll:false] Eshell V5.7.3 (abort with ^G) (test@sungari)1>
Jak widać, w prompcie interpretera pojawił się jego identyfikator sieciowy, składający się z dwóch członów - nazwy interpretera podanej przez -sname i skróconej nazwy komputera. Identyfikatory te będą przydatne na przykład do określenia, na którym interpreterze chcemy wykonać nowy proces. Również mając dany identyfikator już pracującego procesu Pid, możemy dowiedzieć się, na którym interpreterze on pracuje, wywołując funkcję node(Pid). Funkcja node() zaś zwraca identyfikator interpretera, na którym pracuje aktualnie wykonywany proces.
Na początek sprawdźmy, czy interpretery komunikują się ze sobą. W tym celu użyjemy funkcji net_adm:ping:
(test@kerulen)1> net_adm:ping(test@sungari). pong (test@kerulen)2>
Wartość pong oznacza, że wskazany interpreter odpowiedział na komunikat testowy. W przypadku błędu komunikacji wynikiem będzie pang; jeśli Twój interpreter odpowiedział pang, najprawdopodobniej jest to wynikiem nieprawidłowej konfiguracji sieci.
Nowy proces na innym komputerze można uruchomić za pomocą dwuargumentowej odmiany spawn (i spawn_link): pierwszym argumentem jest wtedy identyfikator interpretera, na którym chcemy uruchomić nowy proces. Spróbujmy. Wykonajmy następujące polecenie na komputerze kerulen:
(test@kerulen)2> Pid = spawn(test@sungari, fun() -> io:write(node()) end). test@sungari<5700.45.0> (test@kerulen)3> node(Pid). test@sungari (test@kerulen)4>
Udało się! Nowo utworzony proces, wypisując nazwę swojego interpretera, wypisał test@sungari. Również funkcja node(Pid) odpowiedziała, że nowo utworzony proces znajduje się na sungari. Uruchomiliśmy proces na innym komputerze bez najmniejszego kłopotu!
Z procesem na zdalnym komputerze komunikujemy się dokładnie tak samo, jak z procesami lokalnymi: za pomocą instrukcji ! i receive, tak samo działa również obsługa błędów. Oczywiście ze względu na możliwość występowania problemów z połączeniem nie ma gwarancji, że wysłane komunikaty dotrą do zdalnego procesu, jednakże istnieje gwarancja, że jeśli dotrą, to w tej samej kolejności, w jakiej zostały wysłane. Dzięki temu programy działające w sposób rozproszony pisze się w Erlangu praktycznie tak samo, jak zwykłe programy równoległe.
Omówione w tym artykule cechy Erlanga - sprawna obsługa błędów, wymiana kodu w trakcie pracy programu i łatwe rozproszenie - nie są tylko ciekawostkami; dzięki nim możliwe jest łatwe budowanie programów skalowalnych, odpornych na awarie i o wysokim współczynniku dostępności, co w wielu zastosowaniach jest nie bez znaczenia. Języka Erlang użyto z powodzeniem do oprogramowania przełączników sieciowych (Ericsson AXD301), elementów sieci telefonii komórkowej (system GPRS Ericssona, SMS w T-Mobile), serwerów internetowych (m.in. ejabberd, serwer protokołu XMPP). Znaczenie języka Erlang, lub przynajmniej opisanych tu technik programowania, będzie prawdopodobnie rosnąć, w związku z czym czas poświęcony bliższemu zaznajomieniu z Erlangiem na pewno nie będzie stracony.
Odnośniki:
[1] http://informatyka.wroc.pl/node/470