
Kontynuujemy nasze zmagania na drodze ku stworzeniu syntezatora mowy. Poprzednio [2] opowiedzieliśmy o zamianie tekstu pisanego na ciąg fonemów i skończyliśmy na zaprojektowaniu algorytmu, który takiej zamiany dokonywał. Dziś osiągniemy kolejny stopień wtajemniczenia.
Gdy wiemy już co chcemy mówić, powinniśmy uświadomić sobie jak mówić. W tym artykule nauczymy się obsługiwać pliki dźwiękowe i dowiemy się, jak dokonywać podstawowych przekształceń nagranych głosek (np. zwiększenie głośności). Jednak, by naszą nowo nabytą wiedzę odpowiednio wykorzystać, pogawędzimy też chwilę o akcentach (ich znaczeniu i miejscu występowania), sylabach (co to jest sylaba? jak dzielić słowa na sylaby?) i ogólnie o tym, jak to się dzieje, że ludzka mowa nie jest usypiająca.
Wydawałoby się, że - mając ciągi głosek - nic prostszego teraz jak wziąć nagrania każdej z nich i sklejać je, by otrzymać prosty syntezator. Wybiegając trochę do przodu powiem od razu: tak właśnie będziemy robić (i to już w najbliższej - trzeciej - części!). Jednak zanim zaczniemy, powinniśmy sobie uświadomić, że język mówiony posiada jedną ważną cechę, którą musimy uwzględnić w naszym programie: akcent.
Akcent to - najprościej mówiąc - podkreślenie pewnych sylab w słowie poprzez wymówienie ich w specjalny sposób. W języku polskim przy wymowie sylaby akcentowanej intensywniej wydychamy powietrze, co sprawia, że sylaba jest głośniejsza, dłuższa i ma trochę wyższy ton. Spróbujmy powiedzieć jakiś rozbudowany tekst nie akcentując żadnej z sylab: mowa nasza zabrzmi monotonnie, sztucznie (jak głosy robotów z dawnych filmów Sci-Fi) a co najgorsze - po prostu ciężko będzie nas zrozumieć! Nie chcemy, by nasz syntezator dukał w ten sposób. Nauczymy się zatem, jak zrealizować akcent!
Na początek powiedzmy trochę o dźwiękach, falach, okresach, wycinaniach, rozciąganiach, wydłużaniach i mnożeniach. Inaczej mówiąc, spróbujmy rozwiązać następujące zadanie: zakładamy, że dysponujemy nagraniem pojedynczej głoski i chcemy to nagranie przekształcić tak, by głoska uzyskała akcent. Głoskę uznamy za zaakcentowaną, jeśli powiedziana zostanie:

Rys. 1. Nagranie samogłoski "a".
Zanim zaczniemy, powiedzmy przede wszystkim, że dźwięk jest falą, o której możemy myśleć po prostu jako o funkcji. Na rys.1 i pokazana jest taka właśnie fala dla nagrania samogłoski "a". Zauważmy, że składa się ona z ciągu bardzo podobnych fragmentów, tzw. epok (rys.2), innymi słowy, jest to funkcja okresowa. Niestety tylko teoretycznie, gdyż musimy wziąć pod uwagę jakość nagrania oraz to, że artykulację zawsze trzeba zacząć i skończyć (stąd słabsze fale na początku i końcu).
Uwaga!
Funkcjami okresowymi są jedynie samogłoski, spółgłoski półotwarte i spółgłoski szczelinowe. Dlaczego akurat te? Przypomnijmy sobie, że wymowy pozostałych spółgłosek - zwarto-szczelinowych i zwarto-szczelinowych (o klasyfikacji głosek pisaliśmy tutaj [3]) - nie można "przedłużać", nie brzmią one jednostajnie i siłą rzeczy nie mogą zostać opisane funkcją okresową.

Rys. 2. Pojedyncza epoka.
Audacity pobrać można stąd: http://audacity.sourceforge.net/ [4]
W tym miejscu zachęcam do samodzielnego odkrycia prawideł rządzących zachowaniem fal dźwiękowych produkowanych przez ludzkie narządy artykulacyjne. Do tego celu potrzebny będzie program, pozwalający na podglądanie nagranych głosek - proponuję skorzystać z darmowego Audacity. Czytelniku, spróbuj nagrać tę samą samogłoskę wypowiedzianą w różny sposób: dłużej, krócej; niżej i wyżej; głośniej, ciszej. Porównaj otrzymane nagrania. Nagraj też jakąś spółgłoskę (najlepiej zwartą, np. "d") i porównaj nagranie jej fali z nagraniem samogłoski.
Jeśli nie masz mikrofonu, możesz obejrzeć i porównać nagrania przygotowane przeze mnie:
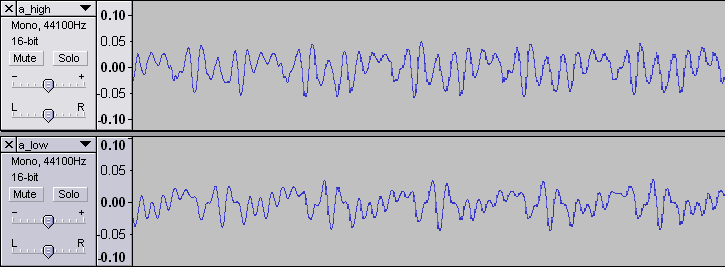
Rys. 3. Porównanie fal samogłoski "a" powiedzianej na wyższym i niższym tonie. Czy zauważasz jakąś prawidłowość?
Po odpowiedniej porcji empirycznych doświadczeń, nadszedł czas by ostatecznie powiedzieć, jak zrealizować trzy potrzebne nam operacje: wydłużenie, podniesienie tonu, zwiększenie głośności.
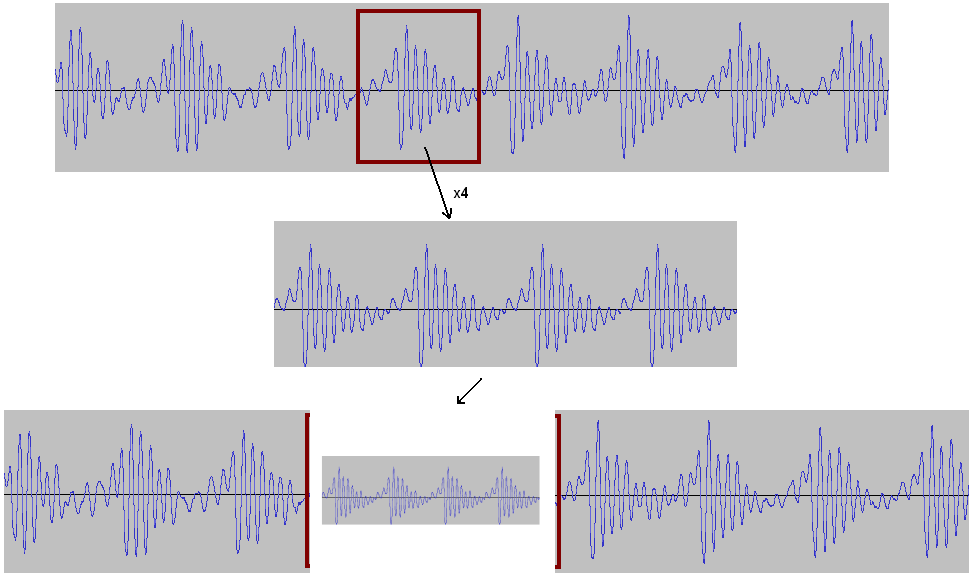
Rys. 4. Wydłużenie czasu trwania samogłoski.
By wydłużyć głoskę należy wziąć jedną epokę i skleić ją ze sobą tyle razy, ile potrzeba. Ta operacja zaprezentowana jest na rys. 4.
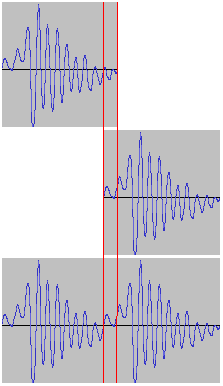 Rys. 5.
Rys. 5.
Przypomnijmy sobie nasze wcześniejsze doświadczenia. Okazuje się, że głoska wypowiadana wyżej wygląda tak samo, tylko epoki są położone bliżej siebie (rys. 3). Korzystając z tej obserwacji, moglibyśmy podnosić ton nagranych głosek przez "ścieśnianie" epok, tak jak zostało pokazane na rys. 5. Epok nie konkatenujemy ze sobą - zamiast tego sprawiamy by mała ich część nachodziła na siebie, co spowoduje, że częstotliwość będzie większa. Pozostaje zastanowić się, co zrobić z nachodzącymi na siebie częściami - najprostszym rozwiązaniem będzie zsumowanie wartości między czerwonymi liniami.
Istnieje alternatywne rozwiązanie problemu podniesienia tonu, wynikające z tego, że wysokość dźwięku zależy po prostu od jego częstotliwości. Zamiast bawić się w przesuwanie epok, możemy ścieśnić całą falę nie przejmując się w ogóle jej strukturą. Jeśli 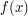 opisuje nagranie głoski, to
opisuje nagranie głoski, to 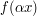 opisuje tę samą głoskę, tyle że o niższym (
opisuje tę samą głoskę, tyle że o niższym (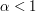 )lub wyższym (
)lub wyższym (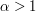 ) tonie.
) tonie.
To najłatwiejsza z transformacji: jeśli dźwięk reprezentowany jest przez funkcję f(x), to funkcja ta pomnożona przez jakąś stałą większą od 1 da ten sam dźwięk, tyle że głośniejszy.
Mówimy sobie tak ogólnie o tym, co należy zrobić i dlaczego, ale pewne przerażenie może budzić myśl o zaimplementowaniu tych wszystkich operacji w jakimś języku programowania. Niepotrzebnie! Pokażemy teraz jak poradzić sobie z obsługą plików wave w języku Python. Nie będziemy wyważać otwartych drzwi i skorzystamy ze standardowej biblioteki wave.
Zanim zaczniemy, parę słów o wyglądzie pliku wave. Otóż każdy plik ma swoją częstotliwość próbkowania, czyli ilość ramek (wartości funkcji) mieszczącej się w jednej sekundzie dźwięku. Standardowo wynosi ona 44100, co oznacza, że jedna sekunda kodowana jest przez 44100 wartości.
Plik wczytamy w ten sposób:
1 2 3 4 5 | import wave file = wave.open(filename) #filename - nazwa pliku wav bytes = file.readframes(file.getnframes()) file.close() |
W zmiennej bytes dostaniemy listę bajtów reprezentujących funkcję dźwięku. Działanie na liście bajtów byłoby jednakże niewygodne - chcielibyśmy po prostu listę wartości. Standardowo pliki "wav" zapisywane są w formacie 16 bitowym, co oznacza, że jedna wartość kodowana jest przez dwa bajty i odpowiada typowi short z języka C.
Sprawdźmy czy rozumiemy. Proste pytanie: jaką długość będzie miała lista bytes, przy założeniu, że plik dźwiękowy trwa jedną sekundę, a częstotliwość próbkowania wynosi 44100?
Pokaż odpowiedź.
Lista będzie miała długość 88200, a to dlatego, że plik miałby 44100 ramek i każda ramka kodowana byłaby przez 2 bajty.
Napiszmy więc funkcję zmieniającą listę bajtów w listę liczb:
1 2 3 4 5 6 7 | import struct #standardowa biblioteka def byte2short(bytelist): vals = [] for i in range(0, len(bytelist), 2): #każde dwa bajty zmieniamy w jednego "shorta" vals.append(struct.unpack('h', bytelist[i]+bytelist[i+1])[0]) return vals |
Od razu napiszmy też funkcję odwrotną - zmieniającą listę wartości w listę bajtów:
1 2 3 4 5 6 7 8 | def short2byte(vallist): bytes = [] for v in vallist: bytes.append(struct.pack('h', v)) #w Pythonie lista bajtów to po prostu string #(każdy znak ma długość jednego bajta) return ''.join(bytes) |
A teraz powiedzmy, że mamy listę wartości fali dźwiękowej i chcemy stworzyć z niej plik wave. Zrobimy to w ten sposób:
1 2 3 4 5 6 7 | W = wave.open("plik.wav", "w") W.setnchannels(1) #ustawiamy ilość kanałów W.setsampwidth(2) #ilość bajtów kodujących jedną ramkę W.setframerate(44100) #częstotliwość próbkowania bytes = short2byte(vallist) #vallist to lista wartości, które chcemy zapisać W.writeframes(bytes) W.close() |
Prawda, że proste? Po zrozumieniu tych paru fragmentów kodu zabawa z plikami "wave" nie będzie nastręczać już żadnych trudności. I wcale nie jest powiedziane, że musimy bawić się w Pythonie - w każdym języku obsługa wave'ów powinna wyglądać mniej więcej tak samo.
Pozostaje jeszcze jedno pytanie: jak szukać epok? Można by napisać program, który robiłby to automatycznie, jednak nie ma takiej potrzeby. Samogłosek jest na tyle mało, że w każdym nagraniu możemy ręcznie odnaleźć numery ramek zawierających jedną epokę i wpisać je do jakiegoś pliku - żeby potem program łatwo je odczytał. Do tego celu doskonale nada się wspominany już program Audacity.
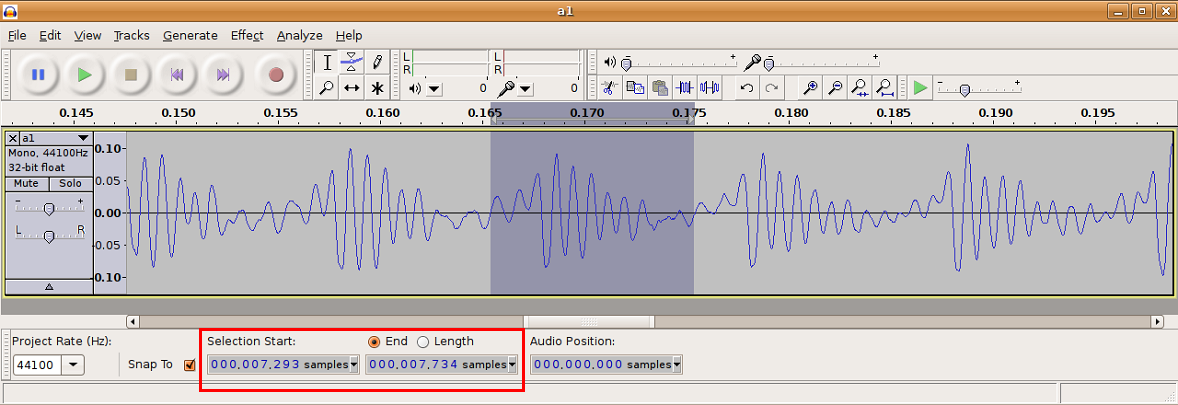
Rys. 5. Szukanie epoki w programie Audacity; epoka znajduje się na ramkach 7293-7734 begin_of_the_skype_highlighting 7293-7734 end_of_the_skype_highlighting.
Wiemy już jak przekształcić nagranie samogłoski tak, aby zabrzmiała ona intensywniej. Pozostaje nam dowiedzieć się, które samogłoski (a ogólniej - sylaby) chcemy w ten sposób zmieniać!
paroksytoniczny - na drugą sylabę od końca
proparoksytoniczny - na trzecią sylabę od końca
Powszechna zasada w języku polskim jest taka, że akcentowana jest druga sylaba od końca. Istnieją jednak wyjątki, które chcielibyśmy uwzględnić. Gdyby się uprzeć, można by je sobie podarować - przecież już teraz językoznawcy uznają za dopuszczalne (szczególnie w mowie potocznej) akcentowanie zawsze na drugą sylabę - nie popełnimy jednak tej zbrodni i w walce o piękno języka sprawimy, by nasz syntezator stawiał akcenty w prawidłowych miejscach. Jest jeszcze jedna motywacja: okazuje się, że przynajmniej w tej kwestii możemy być lepsi od twórców profesjonalnych syntezatorów - wspominana już słynna Ivona z wyjątkami sobie nie radzi...
Wszystkie słowa pochodzenia greckiego kończące się na "-yka", "-ika" powinniśmy akcentować na trzecią sylabę od końca. Powiemy więc ma-te-MA-ty-ka, FI-zy-ka, MU-zy-ka, a nie - ma-te-ma-TY-ka, fi-ZY-ka, mu-ZY-ka. Zasada wydaje się prosta, pytanie - jak ją wyegzekwować? Jasne jest, że nie wystarczy sprawdzić końcówki wyrazów, gdyż - oprócz tego co chcemy - wyłapalibyśmy również wyrazy akcentowane normalnie, dla przykładu: "boryka" ("Zenon boryka się z przeciwnościami losu"), "chodnika" ("Przeszedłem na drugą stronę chodnika") etc. Musimy znaleźć mądrzejszy sposób.
Zauważmy, że jeśli rzeczownik w mianowniku kończy się na "-ika", "-yka", to chcemy go akcentować proparoksytonicznie (czyli na trzecią od końca sylabę). Ach, gdybyśmy tylko mieli zbiór wszystkich rzeczowników w mianowniku! Okazuje się, że marzenie to jest jak najbardziej realne - z pomocą przychodzi nam tzw. słownik morfosyntaktyczny, czyli zbiór wszelkich możliwych odmian słów wraz z informacjami o ich formach gramatycznych. Może to brzmieć trochę niejasno, dlatego zobaczmy, jak wygląda taki słownik dla języka polskiego:
(...) matematyk matematyk subst:sg:nom:m1 matematyk matematyka subst:pl:gen:f matematyka matematyk subst:sg:acc.gen:m1 matematyka matematyka subst:sg:nom:f matematykach matematyk subst:pl:loc:m1 matematykach matematyka subst:pl:loc:f matematykami matematyk subst:pl:inst:m1 matematykami matematyka subst:pl:inst:f matematyki matematyk subst:pl:nom.voc:m1 matematyki matematyka subst:pl:nom.acc.voc:f+subst:sg:gen.dat.loc:f matematykiem matematyk subst:sg:inst:m1 matematyko matematyka subst:sg:voc:f matematykom matematyk subst:pl:dat:m1 matematykom matematyka subst:pl:dat:f matematykowi matematyk subst:sg:dat:m1 matematyku matematyk subst:sg:loc.voc:m1 matematyką matematyka subst:sg:inst:f matematykę matematyka subst:sg:acc:f matematyków matematyk subst:pl:acc.gen:m1 (...)
for line in open('morfologik.txt'): word,base,tag = line.split() (...)
Powyższa lista to fragment pliku polskiego projektu Morfologik. Jego struktura jest prosta, każdą linię tworzą trzy składniki: słowo, forma bazowa, tag. Ten ostatni opisuje formę gramatyczną słowa, dla przykładu tag dla słowa "matematykę" - subst:sg:acc:f - oznacza: rzeczownik (subst), liczba pojedyncza (sg), biernik (acc), rodzaj żeński (f).
My jednakowoż chcemy znaleźć po prostu rzeczowniki (subst), których forma bazowa kończy się na "-yka", -"ika" i których końcówka nie dodaje ani nie odejmuje żadnej samogłoski (tzn. liczba sylab jest taka sama jak liczba sylab w mianowniku). I tak, we fragmencie podanym wyżej, znaleźlibyśmy: matematyka, matematykach, matematyki, matematyko, matematykom, matematyką, matematykę. Hola, hola! - zakrzyknąłby ktoś, i słusznie. Zauważmy, że "matematykach" oznaczać może zarówno osoby zajmujące się matematyką w zdaniu "rozmyślałem wczoraj o tych wszystkich lwowskich matematykach" jak i matematykę ze zdania "z rozrzewnieniem wspominam te nerwy na wszystkich szkolnych matematykach" (w tym wypadku: lekcjach matematyki). Niestety okazuje się, że w zależności od kontekstu te same słowa zaakcentujemy inaczej (proste pytanie: w którym z przytoczonych zdań akcent w słowie "matematykach" padnie na trzecią sylabę?).
Kontekst można rozpoznawać (takie zdanie nazywa się dezambiguacją), jednak wykracza to poza ramy naszego artykułu - być możemy opowiemy o tym zagadnieniu w którejś z kolejnych części. Na razie zaproponujmy proste i chyba satysfakcjonujące rozwiązanie: jeśli daną formę słowa można zaakcentować na dwa sposoby, wybierzmy ten tradycyjny dla języka, tzn. na drugą sylabę od końca, wyjątek czyniąc dla form, które równe są formie bazowej (tzn. "muzyka", "matematyka", "fizyka" itd.). Dzięki temu nasz syntezator uniknie pretensjonalności mówiąc na przykład "uwielbiam słuchać o tych fizykach", a powie pięknie "matematyka królową nauk"!
To jednak nie wszystko. Niektóre formy czasowników również są akcentowane na trzecią sylabę od końca, niektóre - nawet na czwartą! Tak naprawdę łatwiej myśleć o tym jako o enklitykach a nie wyjątkach. Cóż to takiego - enklityka? To sąsiedztwo dwóch wyrazów, z których drugi jest tak zwanym atonem, czyli słowem, w którym w ogóle nie ma akcentu (przykład: "napisz się", gdzie zaimek "się" jest nieakcentowany). Nas jednak interesują mniej oczywiste enklityki, tworzące jedno słowo. Przede wszystkim zaliczyć do nich można formy przeszłe czasowników, takie jak "zrobiliśmy" czy "zrobilibyśmy". W tym ostatnim przypadku akcent padnie na czwartą sylabę od końca, ale łatwiej nie myśleć o tym jak o wyjątku, a - o enklityce właśnie; zauważmy, że równie dobrze moglibyśmy powiedzieć "byśmy zrobili" i znaczenie zostałoby takie same - końcówka jest tak naprawdę osobnym słowem i jedynie ortografia każe nam pisać ją łącznie.
By wyłapać przypadki enklityk, nie będziemy musieli się gimnastykować tak jak w przypadku wyrazów z greki. Okazuje się, że wystarczy proste wyrażenie regularne sprawdzające końcówki wyrazów. Początek funkcji mówiącej, na którą sylabę od końca pada akcent w słowie, mógłby wyglądać w ten sposób:
1 2 3 4 5 6 7 8 9 | import re #wyrażenia regularne def akcent(slowo): if re.search(u'(ła|ło|ły|li)by(śmy|ście)$', slowo): return 4 if ((re.search(u'(ła|ło|ły|li|[uaeyięą]ł)by(m|ś)?$', word) or re.search(u'(ły|li)(ście|śmy)$', slowo))): return 3 |
Wiemy już, na którą sylabę ma padać akcent, pozostaje jednak pytanie: jak tę sylabę odnaleźć w słowie? Inaczej mówiąc: jak dzielić słowa na sylaby?
Moglibyśmy w ogóle zrezygnować z podziału na sylaby i powiedzieć, że chcemy akcentować jedynie samogłoski. Jeśli zatem akcent ma być paroksytoniczny, to szukamy drugiej samogłoski od końca i ją właśnie akcentujemy. Takie podejście nie jest pozbawione sensu, gdyż to przecież samogłoski tworzą istotę sylaby i to one w największej mierze zmieniają brzmienie w sylabach akcentowanych; poza tym o wiele łatwiej jest zmodyfikować brzmienie samogłoski niż spółgłoski, o czym przekonaliśmy się już wcześniej.
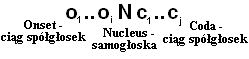
Budowa sylaby
Sylaba dzieli się na trzy części, z których obowiązkowa jest tylko jedna - jądro (nucleus) będące samogłoską. Dwie pozostałe to nagłos (onset), czyli spółgłoski przed samogłoską i wygłos (coda) - spółgłoski po samogłosce.
Załóżmy jednak, że jesteśmy bardziej ambitni i chcemy zaprojektować algorytm dzielący słowa na sylaby. Co to w ogóle jest sylaba? Za Słownikiem języka polskiego PWN: "część wyrazu lub wyraz zawierające jedną samogłoskę lub dyftong, wymawiane jako jedna całość". I wszystko jasne: sylaba to jedna samogłoska plus otaczające ją spółgłoski. Dyftongami się nie przejmujemy - chodzi tu o samogłoski niesylabotwórcze, a my działać będziemy już na ciągach fonemów, w których dyftongi nie występują (np. w słowie "miasto" -> /m j a s t o/ - "i" zostaje zmienione na spółgłoskę /j/).
Skoro środkiem sylaby jest samogłoska, to musimy wiedzieć w którym miejscu rozdzielać ciągi spółgłosek między dwiema samogłoskami. Zobaczmy parę przykładów.
ma-te-ma-ty-ka fi-zy-ka par-ty-tu-ra a-pol-lin róż-dżka (różdż-ka?) o-dy-se-usz chi-me-ra chrząsz-czo-wi (chrzą-szczo-wi?) wy-strze-li-łem (wys-trze-li-łem?)
Spróbujmy zastanowić się, co z owych przykładów wynika:
Opierając się na tych obserwacjach jesteśmy w stanie napisać prosty algorytm podziału na sylaby. Oczywiście nie będzie on idealny, ale w przeważającej większości przypadków zwróci akceptowalny podział. Warto zresztą powiedzieć, że wcale nie potrzebujemy perfekcyjnego algorytmu; cóż to bowiem za różnica, czy do akcentowanej sylaby dorzucimy jedną spółgłoskę więcej czy mniej - naprawdę niewielka.
Nauczyliśmy się dzisiaj obsługiwać pliki dźwiękowe, dowiedzieliśmy - czym w ogóle jest dźwięk, poznaliśmy tajniki akcentowania. Jesteśmy gotowi do stworzenia naszego pierwszego syntezatora. Do zobaczenia w kolejnej części! Niech czas oczekiwania umilą zadania zamieszczone poniżej.
Odnośniki:
[1] http://informatyka.wroc.pl/node/377
[2] http://informatyka.wroc.pl/node/332
[3] http://informatyka.wroc.pl/node/332?
[4] http://audacity.sourceforge.net/
[5] http://informatyka.wroc.pl/upload/synteza/2/a_low.wav
[6] http://informatyka.wroc.pl/upload/synteza/2/a_high.wav
[7] http://informatyka.wroc.pl/upload/synteza/2/u.wav
[8] http://informatyka.wroc.pl/upload/synteza/2/d.wav
[9] http://sourceforge.net/projects/morfologik/files/morfologik/1.5/morfologik-1-5.zip/download
[10] http://informatyka.wroc.pl/upload/synteza/2/a.wav