wav.py
Pokaż/ukryj kod źródłowy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
| #!/usr/bin/python
# -*- coding: utf-8 -*-
import wave
import struct
#słownik przechowujący miejsca epok dla danych samogłosek
periods_dic = dict(
[ (a.split()[0], (a.split()[1], a.split()[2]))
for a in open('data/periods.txt')] )
def phonetimes(filename='data/czasy.txt'):
dic = {}
for line in open(filename):
list, t = line.split()[:-1], line.split()[-1]
for g in list:
dic[g] = float(t)
return dic
#słownik przechowujący czasy trwania poszczególnych głosek
times_dic = phonetimes()
def byte2short(bytelist):
vals = []
for i in range(0, len(bytelist), 2):
vals.append(
struct.unpack('h', bytelist[i]+bytelist[i+1])[0])
return vals
def short2byte(vallist):
bytes = []
for v in vallist:
bytes.append(struct.pack('h', v))
return ''.join(bytes)
def phonetime(phone):
if phone in times_dic:
return times_dic[phone]
else:
return times_dic['*']
def create_wave(filename, bytelist):
W = wave.open(filename,"w")
W.setnchannels(1)
W.setsampwidth(2)
W.setframerate(44100)
W.writeframes(bytelist)
W.close()
def get(phone):
"""zwraca listę bajtów odpowiadających głosce phone"""
P = wave.open('dzwieki/%s.wav' % phone, 'r')
framenumber = int(phonetime(phone) * P.getframerate())
return cut(P.readframes(framenumber))
def getA(phone):
"""zwraca listę bajtów odpowiadających głosce phone,
ale zaakcentowanej"""
P = freq(louder(get_longer(phone)))
return cut(P)
def get_longer(phone, mult = 1.5):
"""zwraca listę bajtów odpowiadających głosce phone,
ale dłuższą mult-razy"""
P = wave.open('dzwieki/%s.wav' % phone, 'r')
framerate = P.getframerate()
P.close()
bytelist = get(phone)
time = mult * len(bytelist)/2/framerate
try:
(start, end) = (int(periods_dic[phone][0]),
int(periods_dic[phone][1]))
except:
return bytelist
ntimes = int(((framerate*float(time) - len(bytelist)/2
+ end - start))
/(end - start))
print time, ntimes
list = byte2short(bytelist)
lengthen = (list[:start]
+ list[start:end]*(ntimes if ntimes > 1 else 2)
+ list[end:])
return short2byte(lengthen[:int(time * framerate)])
def louder(bytelist):
"""podgłaśnia falę reprezentowaną przez bytelist i
również zwraca listę bajtów"""
i, List = 0, []
while i < len(bytelist):
val = struct.unpack('h', bytelist[i]+bytelist[i+1])[0]*2
if val >= 2**15:
val = 2**15 - 1
if val <= -(2**15):
val = -2**15 + 1
List.append(struct.pack('h', val))
i += 2
return ''.join(List)
def freq(bytelist, alfa = 1.05):
""" zwraca g(x) = f(alfa*x) """
from math import floor, ceil
vals = byte2short(bytelist)
g = vals[:1]
i = 1
while ceil(alfa*i) < len(vals):
xa, xb = int(floor(alfa*i)), int(ceil(alfa*i))
ya, yb = vals[xa], vals[xb]
g.append((ya+yb)/((xa+xb)/i))
i += 1
return short2byte(g)
def cutend(bytelist):
"""odcina nagranie od tyłu tak,
zeby fala kończyła się na zerze i szła w górę"""
i = -2
up = False
while True:
val = struct.unpack('h', bytelist[i]+bytelist[i+1])[0]
if val > 0:
up = True
if val <= 0 and up is True:
break
i -= 2
return bytelist[:i]
def cutbegin(bytelist):
"""odcina nagranie od przodu tak,
zeby fala zaczynała od zera i szła w górę"""
i = 0
down = False
while True:
val = struct.unpack('h', bytelist[i]+bytelist[i+1])[0]
if val < 0:
down = True
if val >= 0 and down is True:
break
i += 2
return bytelist[i:]
def cut(bytelist):
"""przycina bytelist z przodu i z tyłu
(patrz opisy funkcji cutend i cutbegin)"""
return cutbegin(cutend(bytelist)) |
To już ostatni moduł naszego programu. Ostatni, ale bardzo ważny - właśnie tutaj zajmiemy się obsługą plików dźwiękowych. Pisaliśmy już trochę o tym, co będziemy chcieli robić i jak tego dokonamy, nie powiedzieliśmy wszak wszystkiego.
Będziemy sklejać nagrania pojedynczych głosek, ale zanim tego dokonamy, musimy je odpowiednio przyciąć. Jeśli złączylibyśmy fale tak po prostu, powstałyby na styku nieprzyjemne trzaski. Przycinaniem zajmuje się funkcja cut(bytelist), spójrzmy na poniższy rysunek:
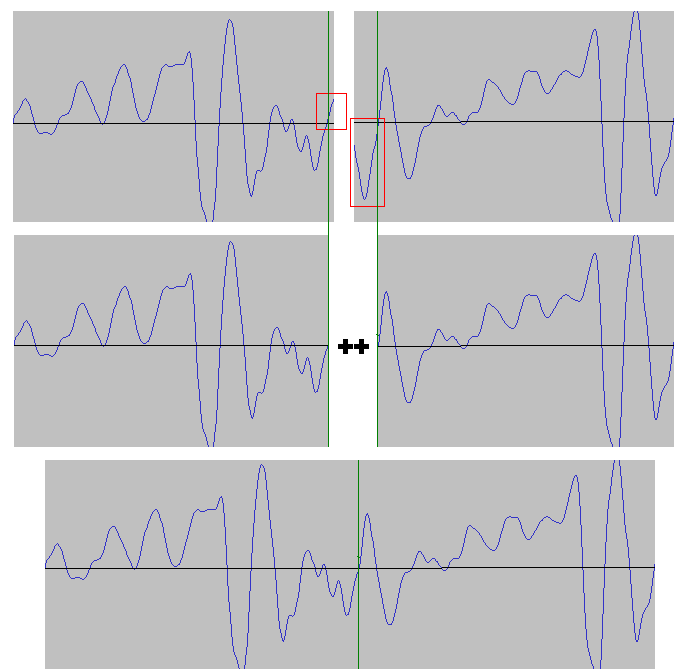
Rys. Zanim połączymy dwa nagrania, musimy odpowiednio przyciąć dwie fale. Chcemy, że zaczynały się i kończyły wartością zero, i żeby rosły zarówno z prawej strony jak i z lewej.
Jest jeszcze jedna ważna sprawa. Nasze nagrania mają fatalną jakość, w szczególności większość głosek brzmi zbyt długo. Zobaczmy jak brzmiałby syntezator gdybyśmy sklejali je tak po prostu, bez żadnej modyfikacji czasu trwania:
Tu powinien być odtwarzacz
Trochę mało naturalnie, prawda? Każda głoska jest wyraźnie wypowiadana osobno a przecież ludzka mowa brzmi zupełnie inaczej. Spróbujemy więc poprzycinać głoski tak, aby uzyskać jak najbardziej naturalne efekty. Do pliku czasy.txt wpisujemy czasy trwania poszczególnych głosek i przy wczytywaniu nagrania ucinamy je tak, by trwało żądaną ilość sekund. Dzięki temu tempo mowy naszego syntezatora jest trochę żywsze:
Pokaż/ukryj zawartość pliku "czasy.txt"
a i o u y d e ni 0.3
ll r w z 0.2
c s f ch k l n m j 0.15
* 0.3
Tu powinien być odtwarzacz
Warto trochę poeksperymentować z czasami, bo ich dobór może znacząco wpływać na jakość mowy naszego syntezatora.
Ważnym elementem programu jest plik periods.txt, przechowujący miejsca epok samogłosek. Dzięki temu, że owe miejsca znamy, możemy wydłużać akcentowane samogłoski. Robimy to tak, jak już kiedyś opisywaliśmy: zwielokrotniamy epokę, której położenie znamy.
Trzy naistotniejsze funkcje, z których korzystają klasy omawiane wcześniej, to: get(phone) (zwraca listę bajtów dla głoski), getA(phone) (zwraca listę bajtów dla samogłoski zaakcentowanej) oraz create_wave(filename, bytelist) (tworzy plik wave).
Funkcje odpowiadające za akcent, tj. wydłużanie, zwiększanie głośności oraz podwyższanie tonu, są dość oczywiste, zresztą już mówiliśmy w jaki sposób powinny działać. Powiedzmy tylko, że podwyższanie tonu realizujemy w prostszy sposób, czyli zwyczajnie ścieśniając funkcję reprezentującą nagranie głoski - nie męczymy się przesuwaniem epok.




