
Synteza mowy II: Akcent i zabawa dźwiękiem
08.03.2010 - Krzysztof Kercz
 PraktykaObsługa plików wave w PythonieMówimy sobie tak ogólnie o tym, co należy zrobić i dlaczego, ale pewne przerażenie może budzić myśl o zaimplementowaniu tych wszystkich operacji w jakimś języku programowania. Niepotrzebnie! Pokażemy teraz jak poradzić sobie z obsługą plików wave w języku Python. Nie będziemy wyważać otwartych drzwi i skorzystamy ze standardowej biblioteki wave. Zanim zaczniemy, parę słów o wyglądzie pliku wave. Otóż każdy plik ma swoją częstotliwość próbkowania, czyli ilość ramek (wartości funkcji) mieszczącej się w jednej sekundzie dźwięku. Standardowo wynosi ona 44100, co oznacza, że jedna sekunda kodowana jest przez 44100 wartości. Plik wczytamy w ten sposób:
W zmiennej bytes dostaniemy listę bajtów reprezentujących funkcję dźwięku. Działanie na liście bajtów byłoby jednakże niewygodne - chcielibyśmy po prostu listę wartości. Standardowo pliki "wav" zapisywane są w formacie 16 bitowym, co oznacza, że jedna wartość kodowana jest przez dwa bajty i odpowiada typowi short z języka C. Sprawdźmy czy rozumiemy. Proste pytanie: jaką długość będzie miała lista bytes, przy założeniu, że plik dźwiękowy trwa jedną sekundę, a częstotliwość próbkowania wynosi 44100? Pokaż odpowiedź. Lista będzie miała długość 88200, a to dlatego, że plik miałby 44100 ramek i każda ramka kodowana byłaby przez 2 bajty. Napiszmy więc funkcję zmieniającą listę bajtów w listę liczb:
Od razu napiszmy też funkcję odwrotną - zmieniającą listę wartości w listę bajtów:
A teraz powiedzmy, że mamy listę wartości fali dźwiękowej i chcemy stworzyć z niej plik wave. Zrobimy to w ten sposób:
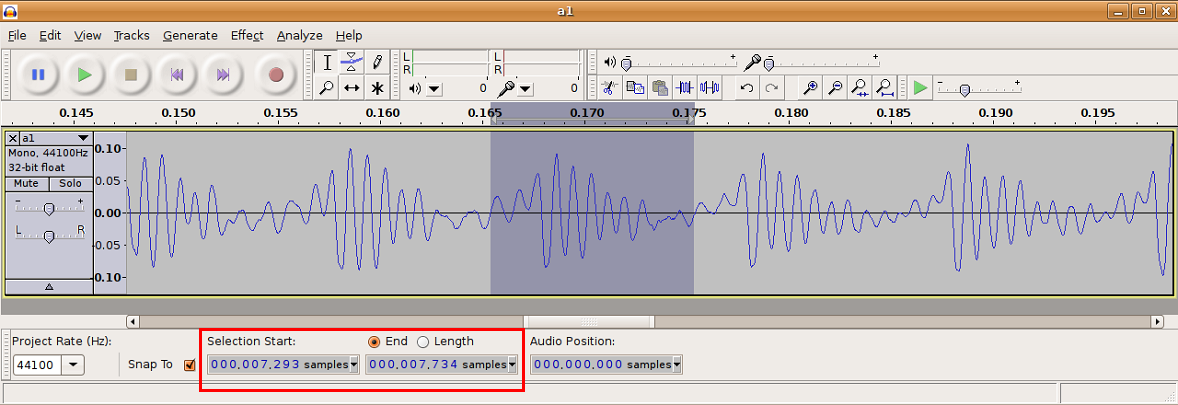
Prawda, że proste? Po zrozumieniu tych paru fragmentów kodu zabawa z plikami "wave" nie będzie nastręczać już żadnych trudności. I wcale nie jest powiedziane, że musimy bawić się w Pythonie - w każdym języku obsługa wave'ów powinna wyglądać mniej więcej tak samo. Szukanie epokiPozostaje jeszcze jedno pytanie: jak szukać epok? Można by napisać program, który robiłby to automatycznie, jednak nie ma takiej potrzeby. Samogłosek jest na tyle mało, że w każdym nagraniu możemy ręcznie odnaleźć numery ramek zawierających jedną epokę i wpisać je do jakiegoś pliku - żeby potem program łatwo je odczytał. Do tego celu doskonale nada się wspominany już program Audacity.
Rys. 5. Szukanie epoki w programie Audacity; epoka znajduje się na ramkach 7293-7734 begin_of_the_skype_highlighting 7293-7734 end_of_the_skype_highlighting. (2 ocen) |
Pod patronatem:



Informacje
- O portalu
- Autorzy
- Mapa portalu
- Zgłoś błąd
Copyright © 2008-2010 Wrocławski Portal Informatyczny
design: rafalpolito.com