
Algorytm Dijkstry
25.11.2009 - Krzysztof Nowicki
 Krok algorytmu wygląda tak:Bierzemy "sąsiada", który jest najbliżej od Możemy napisać własny kopiec jak również, o ile potrafimy, możemy skorzystać z kopca zawartego w stl-u. Kopiec z stl-a pamięta element największy, a my chcemy odzyskiwać element najmniejszy. Można to obejść na dwa sposoby: -Jeśli wartość z kopca jest większa, tzn, że już wcześniej wyciągnęliśmy ten wierzchołek z kopca (z mniejszą propozycją) i nie ma sensu już nic tutaj robić bo już rozważaliśmy ten wierzchołek -Jeśli jest równa (mniejsza być nie może, licząc każdą propozycję uaktualniamy zapis w tablicy odpowiedzi), to możemy być pewni, że odpowiedź wyliczona dla niego jest poprawna, możemy teraz rozważyć jego bezpośrednich sąsiadów i zdecydować czy należy ich wrzucić do kopca. Wystarczy sprawdzić, czy odległość w tablicy odpowiedzi jest mniejsza od tego co proponuje kopiec. Jeśli tak, to w tablicy odpowiedzi należy uaktualić odległość na mniejszą, i wrzucić to do kopca "sąsiadów". Zdarzyć się może, że trzymamy w kopcu wiele razy ten sam wierzchołek (zależy od szczegółowej implementacji), po to są w ogóle te dwa sprawdzenia. Wtedy wyciągając go poraz drugi nie ma sensu liczyć dla niego drugi raz czegokolwiek.
Nieskończoność Własnie tutaj korzystamy z tego, że na początku wszystkie miasta dostały "nieskończoność" na odległość od
Kroki wykonujemy dopóki jeszcze możemy wyciągnąć coś ze zbioru "sąsiadów", po ich wykonaniu otrzymamy w tablicy odległości najkrótsze odległości poszczególnych miast od miasta
Aby sprawdzić tylko długość najkrótszej ścieżki z miasta (10 ocen) |
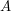 (można w miarę szybko znaleźć takiego sąsiada, jeśli zbiór wszystkich "sąsiadów" trzymamy w kopcu, który pamięta nam element najmniejszy).
(można w miarę szybko znaleźć takiego sąsiada, jeśli zbiór wszystkich "sąsiadów" trzymamy w kopcu, który pamięta nam element najmniejszy). 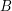 możemy zakonczyć działanie algorytmu w momencie, w którym
możemy zakonczyć działanie algorytmu w momencie, w którym Pod patronatem:



Informacje
- O portalu
- Autorzy
- Mapa portalu
- Zgłoś błąd
Copyright © 2008-2010 Wrocławski Portal Informatyczny
design: rafalpolito.com