
Gdy człowiek staje się hasłem
31.05.2011 - Paweł Hałdrzyński
 Czy rzeczywiście (bez)błędnie?Część osób próbuje porównać biometrykę do zwykłego wpisywania hasła. Istnieje jednak pewna różnica. Wpisując dane hasło, system bezpieczeństwa przepuści nas tylko wtedy, gdy w bazie znajdzie identyczne hasło. Z biometrią jest inaczej. Szansa wygenerowania identycznego obrazu podczas uwierzytelniania jaki zachowany został w procesie rejestracji jest wręcz niemożliwa. Zauważmy, że praktycznie nigdy nie uda nam się w identyczny sposób przyłożyć palca do czytnika linii papilarnych. Obraz naszej twarzy będzie również inny w zależności od posiadanej miny (uśmiech, smutek), a cechy behawioralne (jak tempo pisania) zależne jest od naszego samopoczucia. Gdybyśmy sprawdzali stuprocentową dokładność odczytywanych danych ze wzorcem, systemy biometryczne nigdy nie dokonałyby naszej autoryzacji. Dwa współczynnikiPobierając dane od użytkownika nigdy nie będziemy w stanie wytworzyć identycznych warunków, jakie miały miejsce podczas jego rejestracji. Różnice będą polegać na ustawieniu czytnika (np. nigdy nie ułożymy palca na czytniku w ten sam sposób), warunkach atmosferycznych (temperatura, wilgotność powietrza), a także na samopoczuciu danej osoby. Stąd algorytm porównujący odczytane cechy musi posiadać pewny wskaźnik akceptowalności. Im bardziej będziemy restrykcyjni wobec logujących się użytkowników, tym bardziej uciążliwy proces weryfikacji będą oni zmuszeni przechodzić. Z drugiej jednak strony, jeśli zwiększymy wskaźnik akceptowalności błędu, wtedy nasz system zabezpieczeń biometrycznych osłabnie. Kluczową więc rolą jest dobranie takich parametrów komparatora cech, aby system biometryczny był bezpieczny i jak najmniej uciążliwy. Pomogą nam w tym dwa podstawowe wskaźniki – FAR i FRR. FAR i FRRKiedy pierwszy raz używamy systemu biometrycznego musimy się zarejestrować. Wprowadzamy więc swoje dane biometryczne, które zostają zapisane jako szablon i od tej pory będą one przechowywane w bazie danych wraz z informacją do kogo należą. Nareszcie możemy się zalogować. Wprowadzane przy logowaniu dane za każdym razem porównywane są z zapisanymi w bazie szablonami. Algorytm porównywania zwróci nam jedną z dwóch informacji: akceptacja lub odrzucenie (odpowiednio: jeśli porównanie się udało/nie udało). To, jak dokładnym algorytmem porównania będzie posługiwał się komparator cech można zdefiniować za pomocą dwóch wartości: FAR i FRR. FAR, czyli False Acceptance Rate oraz FRR – False Rejection Rate, to dwa podstawowe wskaźniki odpowiedzialne za błędy w odczytach danych biometrycznych. Pierwszy z nich mówi nam, ile błędnych próbek biometrycznych system uzna za poprawne. Z kolei FRR mówi ile pozytywnych porównań zostało oznaczonych negatywnie. Wartości te są inne dla różnych urządzeń biometrycznych. Załóżmy, że nasz system biometryczny przechowuje szablon pewnej osoby. Nazwijmy ją osobą N, która zamierza przejść etap weryfikacji. Spróbujmy teraz przewidzieć jaka jest szansa, że N nie zaloguje się do systemu. Obliczmy prawdopodobieństwo braku sukcesu dla zarejestrowanej osoby [FRR(N)]: 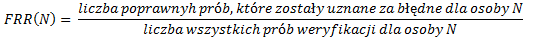
Oznacza to, że jeśli podczas 1000 prób logowania, 10 z nich komparator uzna za błędne, to FRR(N)=0.01. 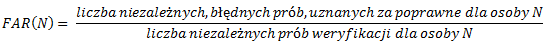
W naszym przypadku słowo „niezależny" oznacza, że próbki biometryczne pobierane są od różnych osób. Jeśli w grupie 1000 różnych osób znajdziemy 10, które mogą zalogować się na konto N, to FAR(N)=0.01. 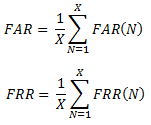 Do tej pory przyglądaliśmy się jedynie weryfikacji. Dostawaliśmy ID (login) oraz wejściowe dane biometryczne, które zostawały porównywane z odpowiednim szablonem w bazie danych (i co najistotniejsze, mieliśmy tylko jedno porównanie). Zajmijmy się identyfikacją. Tym razem musimy dokonać tyle porównań, ilu użytkowników mamy zarejestrowanych.
Rozpatrzmy bazę, w której mamy N różnych szablonów. Wprowadźmy następujące oznaczenia: FARN – niesłuszne zaakceptowanie dla naszej N-osobowej bazy, oraz FRRN – nieudana identyfikacja, również dla N-osobowej bazy. FAR i FRR pozwalają nam zdefiniować rzeczywiste bezpieczeństwo danej biometrii. Myśląc nad wyborem odpowiedniego urządzenia do zabezpieczeń biometrycznych powinniśmy kierować się właśnie tymi współczynnikami. Musimy również pomyśleć nad pewnym kompromisem. Im wyższy wskaźnik FRR, tym bardziej niewygodny w użytkowaniu staje się nasz system. Analogicznie sytuacja wygląda ze współczynnikiem FAR. Zaopatrując się w system z ustawieniami FAR = 1 oraz FRR = 0 dostajemy zupełnie niezabezpieczony system. Tymczasem FAR = 0 i FRR = 1 to ustawienia systemu, który nie zaakceptuje nikogo. (1 ocena) |
Pod patronatem:



Informacje
- O portalu
- Autorzy
- Mapa portalu
- Zgłoś błąd
Copyright © 2008-2010 Wrocławski Portal Informatyczny
design: rafalpolito.com